PostgreSQL WITH RECURSIVE — 재귀 CTE로 트리 구조 탐색하기
PostgreSQL의 WITH RECURSIVE를 사용하여 트리·계층 구조 데이터를 단일 쿼리로 탐색하는 방법을 정리합니다. Working Table 동작 원리, UNION vs UNION ALL 선택 기준, 실제 쿼리 개선 사례를 다룹니다.


파일 시스템의 폴더 구조처럼 부모-자식 관계로 이루어진 트리 데이터를 데이터베이스에서 조회해야 할 때가 있습니다. 특정 폴더에서 루트까지의 경로를 구하거나, 조직도에서 상위 부서를 역추적하는 경우가 대표적입니다.
파일 시스템 트리 조회 쿼리에서 재귀 CTE의 구조를 개선한 적이 있습니다.
기존 쿼리도 WITH RECURSIVE를 사용하고 있었지만, Anchor에 파일 레코드가 혼입되고 UNION ALL로 중복이 누적된 뒤 외부에서 SELECT DISTINCT로 걸러내는 구조여서 API 응답에 1.6분이 걸리고 있었습니다.
재귀 CTE는 Anchor와 Recursive 각 단계에서 조건을 사전 필터링할 수 있고, UNION으로 매 단계 중복을 제거할 수 있어 후처리 없이 정제된 결과를 반환할 수 있습니다.
개선 과정에서 Working Table이 정확히 어떻게 동작하는지, UNION과 UNION ALL의 차이가 재귀에서 어떤 영향을 주는지 등 구조적으로 헷갈렸던 부분이 있었습니다.
이 글에서는 그때 정리한 내용을 바탕으로 재귀 CTE의 동작 원리를 먼저 다룬 뒤, 실제 쿼리를 어떻게 개선했는지 다룹니다.
CTE와 재귀 CTE
CTE(Common Table Expression)는 WITH 절로 정의하는 이름 있는 임시 결과 집합입니다.
서브쿼리에 이름을 붙여 분리할 수 있어 가독성이 높아지고, 같은 쿼리 안에서 여러 번 참조할 수 있습니다.
-- 일반 CTE 예시
WITH active_users AS (
SELECT * FROM users WHERE status = 'ACTIVE'
)
SELECT * FROM active_users WHERE created_at > '2026-01-01';재귀 CTE는 여기에 RECURSIVE 키워드를 추가하여, CTE가 자기 자신을 참조할 수 있게 한 것입니다.
SQL에서 트리·계층 구조 데이터를 단일 쿼리로 탐색하는 패턴입니다.
반복문의 SQL 버전으로, Anchor(시작점)에서 출발하여 종료 조건을 만족할 때까지 자기 자신을 반복 참조하며 결과를 누적합니다.
| 항목 | 설명 |
|---|---|
| 목적 | 트리·계층 구조를 단일 쿼리로 탐색 |
| 핵심 구조 | Anchor (시작점) + UNION + Recursive (반복부) |
| 종료 조건 | Recursive 부분이 빈 결과를 반환하면 자동 종료 |
| DBMS 지원 | PostgreSQL, MySQL 8.0+, SQL Server, Oracle |
| 주요 용도 | 폴더 트리 탐색, 조직도, BOM(부품 구조), 경로 탐색 |
기본 구문
WITH RECURSIVE cte_name AS (
-- ① Anchor: 시작 데이터 (반복문의 초기값)
SELECT ...
UNION -- 또는 UNION ALL
-- ② Recursive: 직전 단계의 새 행을 입력으로 다음 결과 생성
SELECT ... FROM table JOIN cte_name ...
-- ③ 종료: Recursive가 빈 결과를 반환하면 자동 종료
)
SELECT * FROM cte_name;프로그래밍 반복문과의 대응
| 재귀 CTE | 프로그래밍 |
|---|---|
| Anchor | 초기값 설정 (i = 0) |
| Recursive 부분 | 반복 본문 (i++) |
| 빈 결과 반환 | break 조건 |
| UNION으로 누적 | results.append() |
| Working Table (직전 단계의 새 행) | 이전 루프에서 가장 마지막에 추가한 항목 (results[-1]) |
# 폴더 C(item_seq=4)에서 루트까지 역추적하는 예시
# 테이블 데이터: item_seq → {file_name, parent_no}
table = {
1: {"file_name": "/", "parent_no": None},
2: {"file_name": "A", "parent_no": 1},
3: {"file_name": "B", "parent_no": 2},
4: {"file_name": "C", "parent_no": 3},
}
working_table = [4] # Anchor: 시작 item_seq
result_table = []
while working_table: # 빈 리스트가 되면 종료
result_table.extend(working_table) # UNION: 결과에 누적
next_rows = []
for seq in working_table: # 직전 단계의 새 행만 처리
parent_no = table[seq]["parent_no"]
if parent_no is not None:
next_rows.append(parent_no)
working_table = next_rows # 새로 찾은 행으로 교체
# result_table = [4, 3, 2, 1] → C, B, A, /종료 조건
Recursive 부분의 JOIN이 더 이상 매칭되는 행을 찾지 못하면 빈 결과(empty set)를 반환합니다. 빈 결과가 반환되면 재귀가 자동 종료됩니다.
-- 예: parent_no = NULL인 루트에 도달하면
JOIN tree t ON p.item_seq = t.parent_no
-- t.parent_no = NULL → p.item_seq = NULL인 행 없음 → 빈 결과 → 종료주의
종료 조건이 만족되지 않으면 무한 루프에 빠집니다.
PostgreSQL은 기본적으로 재귀 깊이 제한이 없으므로,
순환 참조가 있는 데이터에서는 CYCLE 절이나 깊이 제한 조건을 추가해야 합니다.
단계별 실행 과정
예시 테이블
폴더 구조를 저장하는 테이블이 있다고 가정합니다.
file_structure_t
┌──────────┬───────────┬───────────┐
│ item_seq │ file_name │ parent_no │
├──────────┼───────────┼───────────┤
│ 1 │ / │ NULL │ ← 루트
│ 2 │ A │ 1 │
│ 3 │ B │ 2 │
│ 4 │ C │ 3 │ ← 대상 파일이 여기 있음
└──────────┴───────────┴───────────┘
트리 구조:
/ (1)
└── A (2)
└── B (3)
└── C (4) ← 대상 파일 존재 폴더쿼리
WITH RECURSIVE tree AS (
-- Anchor: 대상 파일이 있는 폴더부터 시작
SELECT item_seq, file_name, parent_no
FROM file_structure_t
WHERE item_seq = 4
UNION
-- Recursive: 부모 폴더를 찾아 올라감
SELECT p.item_seq, p.file_name, p.parent_no
FROM file_structure_t p
JOIN tree t ON p.item_seq = t.parent_no
)
SELECT * FROM tree;Working Table 동작 원리
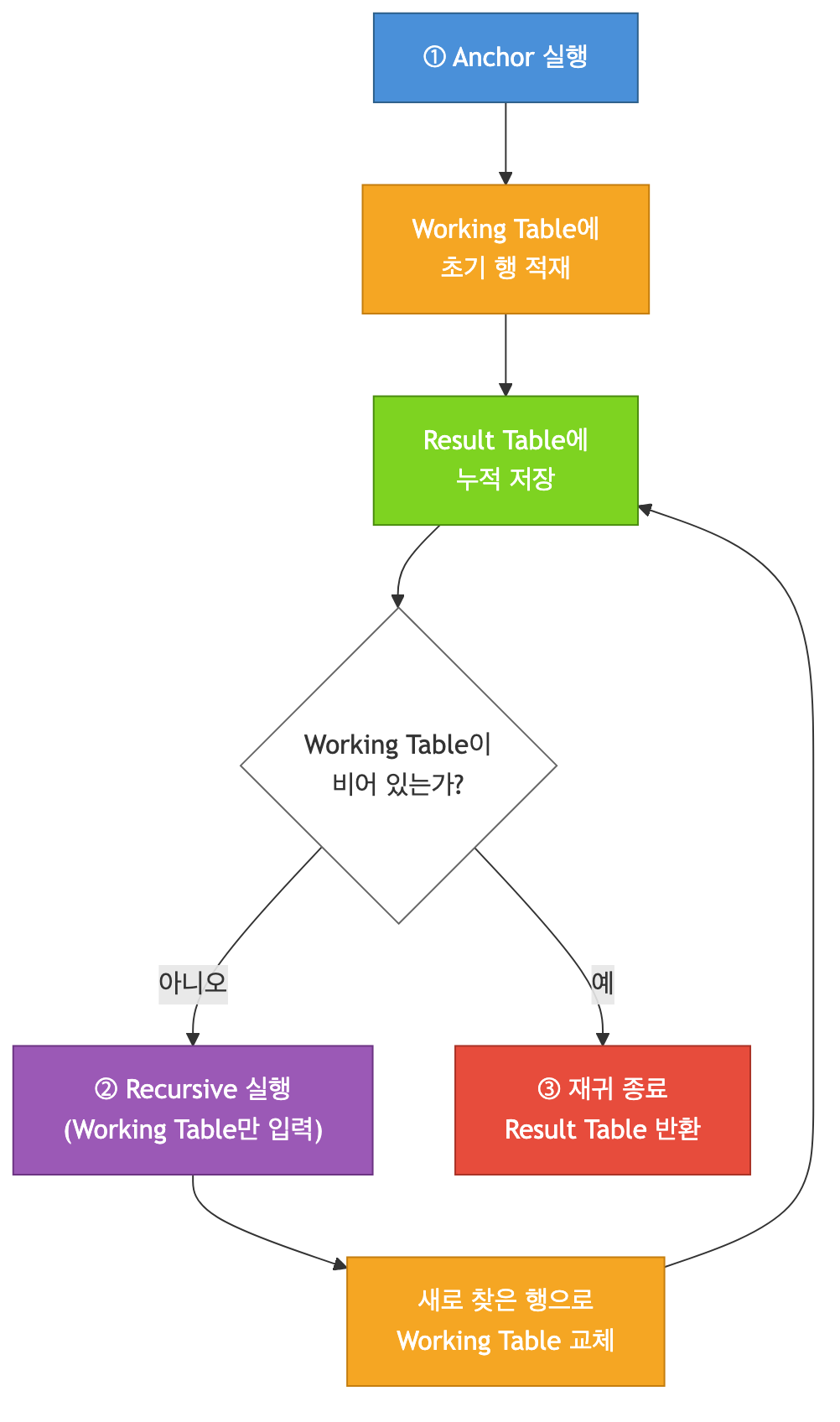
PostgreSQL의 재귀 CTE는 내부적으로 Working Table과 Result Table 두 가지를 관리합니다.
Recursive 부분에서 JOIN tree t로 참조하는 tree는 전체 누적 결과가 아니라 직전 단계에서 새로 추가된 행(Working Table)만을 의미합니다.
이 구분이 중요한 이유는 성능과 정확성 때문입니다. 만약 매 단계마다 전체 누적 결과를 입력으로 사용하면, 이미 처리한 행을 다시 처리하게 되어 중복 탐색과 무한 루프의 위험이 생깁니다. Working Table 방식은 새로 발견된 행만 다음 단계로 전달하여 효율적이고 안전하게 동작합니다.
Step별 추적
Step 1 — Anchor 실행
item_seq = 4인 행을 시작점으로 선택합니다.
Working Table = [C] Result Table = [C]Step 2 — 1차 재귀
Working Table [C]에서 t.parent_no = 3을 가져와 p.item_seq = 3인 행을 찾습니다.
SELECT p.* FROM file_structure_t p
JOIN tree t ON p.item_seq = t.parent_no
-- 3 = 3 ✅ 매칭Working Table = [B] Result Table = [C, B]Step 3 — 2차 재귀
Working Table [B]에서 t.parent_no = 2 → p.item_seq = 2 매칭.
Working Table = [A] Result Table = [C, B, A]Step 4 — 3차 재귀
Working Table [A]에서 t.parent_no = 1 → p.item_seq = 1 매칭.
Working Table = [/] Result Table = [C, B, A, /]Step 5 — 4차 재귀 (종료)
Working Table [/]에서 t.parent_no = NULL → p.item_seq = NULL인 행 없음 → 빈 결과 → 재귀 종료.
최종 결과
SELECT * FROM tree:
┌──────────┬───────────┬───────────┐
│ item_seq │ file_name │ parent_no │
├──────────┼───────────┼───────────┤
│ 4 │ C │ 3 │
│ 3 │ B │ 2 │
│ 2 │ A │ 1 │
│ 1 │ / │ NULL │
└──────────┴───────────┴───────────┘
→ C에서 루트(/)까지 전체 경로가 한 번의 쿼리로 추출됨핵심 규칙
UNION vs UNION ALL
| 항목 | UNION | UNION ALL |
|---|---|---|
| 중복 처리 | 제거 | 허용 |
| 성능 | 느림 (중복 검사 비용) | 빠름 |
| 재귀 반복 | 중복 행은 재귀에서 제외 | 중복 행도 재귀 대상 |
여러 시작점이 같은 조상을 공유하는 경우를 생각해 봅니다.
대상 폴더: C (parent=B), D (parent=B)
→ B가 두 번 Anchor에 잡힘
→ B의 부모 A도 두 번 재귀됨
UNION: A는 1번만 결과에 포함, 불필요한 재귀 반복 방지
UNION ALL: A가 2번 결과에 포함, 같은 경로를 중복 탐색선택 기준:
| 상황 | 권장 |
|---|---|
| 여러 시작점이 같은 조상을 공유 | UNION (중복 제거, 불필요한 재귀 방지) |
| 시작점이 하나이거나 경로가 겹치지 않음 | UNION ALL (성능 우위) |
| 순환 참조 가능성 | UNION (무한 루프 방지) |
CTE 간 참조 규칙
같은 WITH 블록 안에서 앞서 정의된 CTE는 뒤의 CTE에서 자유롭게 참조할 수 있습니다.
WITH
cte_a AS (...),
cte_b AS (... SELECT FROM cte_a ...), -- ✅ cte_a 참조 가능
cte_c AS (... SELECT FROM cte_a, cte_b ...) -- ✅ 둘 다 참조 가능
SELECT * FROM cte_c;규칙은 하나입니다. 정의 순서상 자기보다 위에 선언된 CTE만 참조 가능합니다.
WITH
cte_a AS (... SELECT FROM cte_b ...), -- ❌ cte_b가 아직 정의 안 됨
cte_b AS (...)RECURSIVE 선언 규칙
CTE 안에서 자기 자신을 참조하려면 반드시 WITH RECURSIVE 선언이 필요합니다.
-- ✅ RECURSIVE 선언 → 자기 자신 참조 가능
WITH RECURSIVE tree AS (
SELECT ... UNION SELECT ... FROM table JOIN tree ...
)
-- ❌ RECURSIVE 없음 → 자기 자신 참조 불가 (에러)
WITH tree AS (
SELECT ... UNION SELECT ... FROM table JOIN tree ...
)WITH RECURSIVE를 한 번만 선언하면 블록 내에서 재귀 CTE를 여러 개 선언할 수 있습니다.
WITH RECURSIVE
cte_a AS (... UNION SELECT ... FROM cte_a ...), -- 재귀 ✅
cte_b AS (... UNION SELECT ... FROM cte_b ...), -- 재귀 ✅
cte_c AS (SELECT 1 AS num) -- 일반 CTE ✅
SELECT ...RECURSIVE는 재귀를 허용한다는 선언이지, 반드시 재귀해야 한다는 강제가 아닙니다.
선언만 하고 모든 CTE를 일반 CTE로 사용해도 정상 동작하며, 성능에도 영향을 주지 않습니다.
재귀 CTE가 되는 조건
아래 세 가지를 모두 만족해야 재귀 CTE로 동작합니다. 하나라도 빠지면 일반 CTE입니다.
WITH RECURSIVE블록 안에 선언되어 있다UNION또는UNION ALL로 두 SELECT를 연결한다- 두 번째 SELECT에서 자기 자신을 참조한다
기존 쿼리의 문제
재귀 CTE의 동작 원리를 이해했으니, 실제로 어떤 구조가 문제였는지 살펴봅니다.
기존 쿼리는 조회하려는 파일이 있는 폴더에서부터 루트 디렉토리까지 역추적하는 재귀 쿼리였습니다. 동작은 했지만 세 가지 구조적 비효율이 있었고, 실제로 트리 조회 API의 서버 응답 시간이 1.6분에 달했습니다.
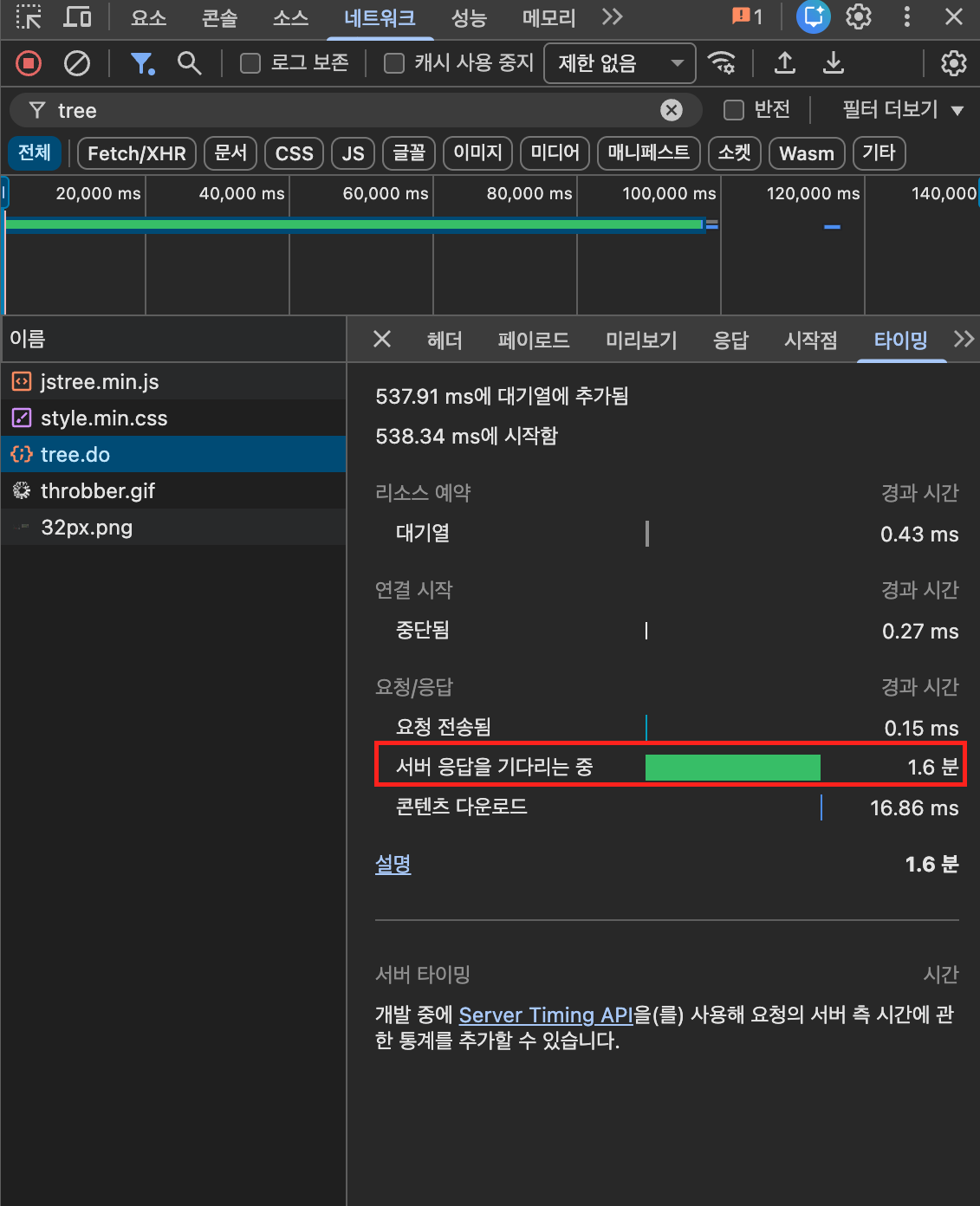
1. Anchor에 파일 레코드가 포함됨
-- Anchor: file_full_path로 매칭 → 파일(COM_FLE) 레코드까지 포함
WHERE EXISTS (
SELECT 1 FROM file_paths f
WHERE f.file_path = s.file_full_path
)대상 파일의 경로(file_path)와 파일 구조 테이블의 전체 경로(file_full_path)를 직접 매칭하므로, 파일 레코드 자체가 Anchor에 포함됩니다.
파일 레코드는 디렉토리가 아니므로 트리 구성에 불필요하지만, 일단 재귀 대상에 들어간 뒤 외부 WHERE에서 걸러지는 구조입니다.
2. UNION ALL + DISTINCT
-- 재귀 내부: 중복 허용
UNION ALL
-- 외부: 전체 결과에서 중복 제거
SELECT DISTINCT(a.*) FROM ( ... ) a
WHERE folder_type = 'COM_DIR'UNION ALL은 중복을 허용하므로, 여러 대상 파일이 같은 조상 폴더를 공유하면 해당 폴더가 여러 번 재귀됩니다.
이 중복을 제거하기 위해 외부에서 SELECT DISTINCT를 사용하는데, 이는 전체 결과를 한꺼번에 비교하므로 행 수가 많을수록 비용이 큽니다.
3. 중첩 서브쿼리 구조
SELECT DISTINCT(a.*) FROM (
WITH RECURSIVE treeA AS ( ... )
SELECT * FROM treeA
) a
WHERE folder_type = 'COM_DIR'재귀 CTE가 서브쿼리 안에 중첩되어 있고, 결과 필터링이 외부 WHERE에서 이루어집니다.
쿼리 자체가 복잡해질 뿐 아니라, folder_type = 'COM_DIR' 조건이 재귀 내부가 아닌 외부에 있어 불필요한 행까지 재귀 대상에 포함됩니다.
개선된 쿼리
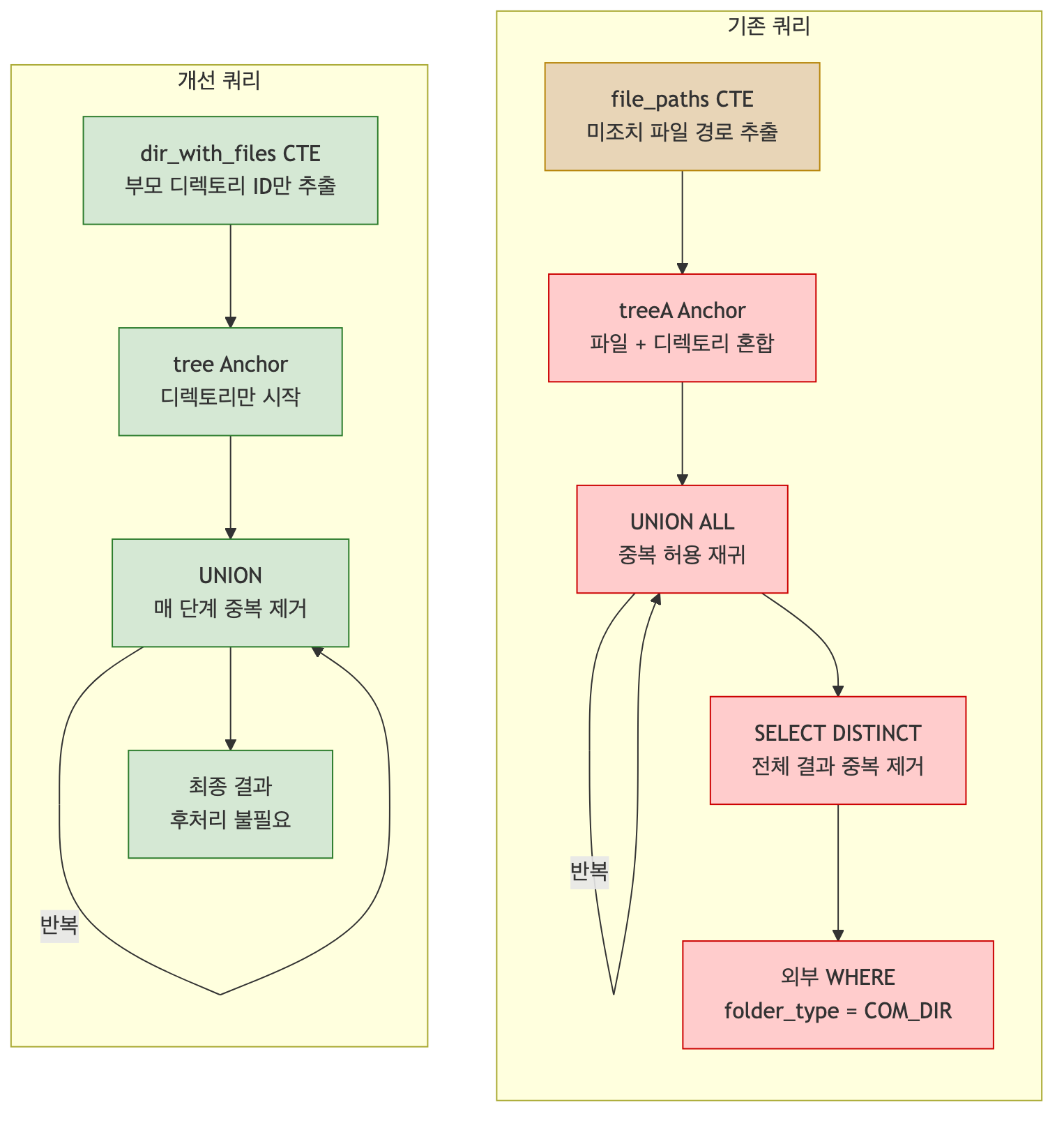
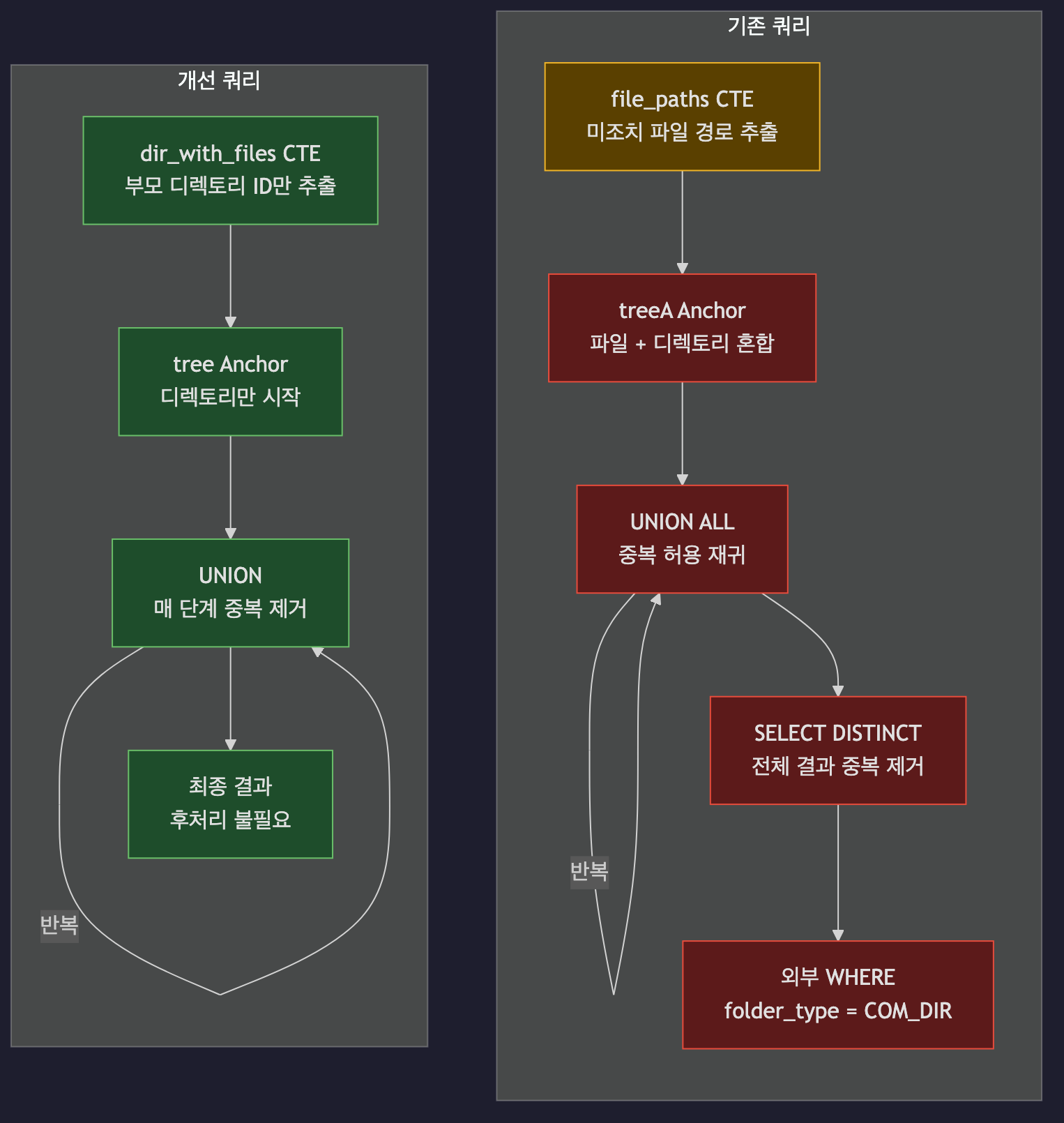
기존 쿼리의 세 가지 문제를 해결한 구조입니다.
개선 포인트
1. Anchor를 디렉토리로 한정
-- 일반 CTE: 대상 파일의 부모 디렉토리 ID만 추출
dir_with_files AS (
SELECT DISTINCT s.parent_no AS item_seq
FROM ... WHERE s.folder_type = 'COM_FLE'
)
-- Anchor: 디렉토리만 시작점으로 사용
WHERE d.item_seq IN (SELECT item_seq FROM dir_with_files)
AND d.folder_type = 'COM_DIR'파일 레코드의 parent_no(부모 디렉토리 ID)를 먼저 추출하고, 이를 Anchor의 시작점으로 사용합니다.
파일 레코드는 처음부터 재귀 대상에서 제외되므로, 외부에서 folder_type = 'COM_DIR'로 걸러낼 필요가 없습니다.
2. UNION으로 매 단계 중복 제거
UNION -- UNION ALL 대신 UNION 사용UNION은 매 재귀 단계마다 중복을 제거합니다.
여러 대상 폴더가 같은 조상을 공유하더라도 한 번만 재귀되므로, 외부 DISTINCT가 필요 없습니다.
3. 플랫한 CTE 체인
WITH RECURSIVE
dir_with_files AS ( ... ), -- 일반 CTE
tree AS ( ... ) -- 재귀 CTE
SELECT * FROM tree ORDER BY file_full_path중첩 서브쿼리 대신 CTE를 순서대로 나열하는 플랫한 구조입니다. 각 CTE의 역할이 명확하고, 결과가 재귀 내부에서 이미 정제되어 나오므로 후처리가 불필요합니다.
비교 요약
| 항목 | 기존 | 개선 |
|---|---|---|
| Anchor 시작점 | 파일 + 디렉토리 혼합 | 디렉토리만 |
| 중복 처리 | UNION ALL + 외부 DISTINCT | UNION (매 단계 자동 제거) |
folder_type 필터 | 외부 WHERE 후처리 | Anchor/Recursive 양쪽 사전 필터 |
| 쿼리 구조 | 중첩 서브쿼리 | 플랫 CTE 체인 |
| 불필요한 재귀 | 파일 레코드도 재귀 대상 | 디렉토리만 재귀 대상 |
성능 결과
구조 개선 후 동일한 tree.do API의 서버 응답 시간이 1.6분(96초)에서 740ms로 약 130배 단축되었습니다.
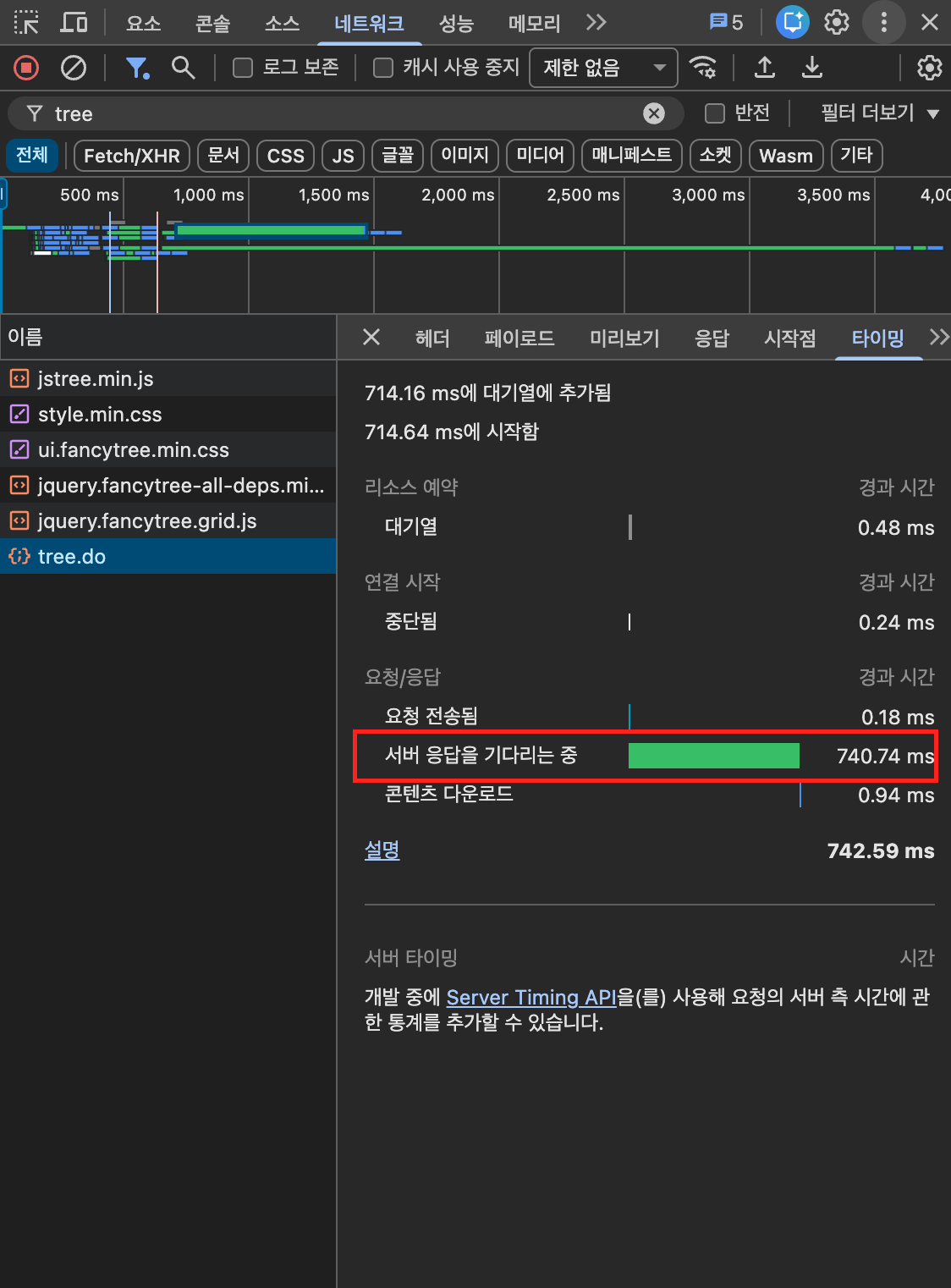
| 항목 | 기존 | 개선 |
|---|---|---|
| 서버 응답 시간 | 1.6분 | 740ms |
Anchor에서 불필요한 파일 레코드를 제외하고, UNION으로 매 단계 중복을 제거한 것만으로 쿼리 실행 시간이 대폭 줄었습니다.
SELECT DISTINCT 후처리가 사라진 것도 큰 요인입니다. 전체 결과를 모아서 한꺼번에 비교하는 것보다, 매 단계 소량의 행만 비교하는 UNION이 훨씬 효율적입니다.
주의사항
순환 참조
부모-자식 관계에 순환이 있으면(A → B → C → A) 재귀가 끝나지 않습니다.
UNION을 사용하면 이미 방문한 행을 제외하므로 순환을 감지할 수 있지만, UNION ALL에서는 무한 루프에 빠집니다.
PostgreSQL 14 이상에서는 CYCLE 절로 순환을 감지할 수 있습니다.
WITH RECURSIVE tree AS (
SELECT item_seq, parent_no FROM file_structure_t WHERE item_seq = 4
UNION ALL
SELECT p.item_seq, p.parent_no FROM file_structure_t p
JOIN tree t ON p.item_seq = t.parent_no
)
CYCLE item_seq SET is_cycle USING path
SELECT * FROM tree WHERE NOT is_cycle;깊이 제한
재귀 깊이가 깊어지면 성능이 저하될 수 있습니다. 깊이 카운터를 추가하여 제한을 걸 수 있습니다.
WITH RECURSIVE tree AS (
SELECT item_seq, parent_no, 1 AS depth
FROM file_structure_t WHERE item_seq = 4
UNION ALL
SELECT p.item_seq, p.parent_no, t.depth + 1
FROM file_structure_t p
JOIN tree t ON p.item_seq = t.parent_no
WHERE t.depth < 100 -- 최대 100단계
)
SELECT * FROM tree;인덱스
재귀 CTE의 성능은 JOIN 조건에 사용되는 컬럼의 인덱스에 크게 좌우됩니다.
위 예시에서는 item_seq와 parent_no에 인덱스가 있어야 매 재귀 단계의 조회가 빠릅니다.
UNION vs UNION ALL 성능 트레이드오프
UNION은 매 단계 중복 검사 비용이 있으므로, 중복이 발생하지 않는 구조에서는 UNION ALL이 더 효율적입니다.
시작점이 하나이거나 경로가 겹치지 않는 경우에는 UNION ALL을 선택하는 것이 좋습니다.
참고
- 재귀 CTE↑
- WITH RECURSIVE 블록 안에서 UNION 또는 UNION ALL로 Anchor(시작점)와 Recursive(반복부)를 연결한 CTE이다. Recursive 부분이 빈 결과를 반환할 때까지 자기 자신을 반복 참조하며, 매 단계의 새로운 행만 다음 단계로 전달하는 Working Table 메커니즘으로 동작한다.
- CTE (Common Table Expression)↑
- WITH 절 안에서 SELECT 문에 이름을 붙여 정의하는 임시 결과 집합이다. 서브쿼리를 별도 이름으로 분리하여 가독성을 높이고, 같은 쿼리 안에서 여러 번 참조할 수 있다. RECURSIVE 키워드를 추가하면 자기 자신을 참조하는 재귀 CTE를 작성할 수 있다.
- Working Table↑
- PostgreSQL 재귀 CTE는 내부적으로 Working Table과 Result Table 두 가지를 관리한다. Recursive 부분에서 CTE 이름으로 참조하는 것은 전체 누적 결과가 아니라 직전 단계에서 새로 추가된 행(Working Table)만이다. 이 방식 덕분에 이미 처리한 행을 다시 처리하지 않아 효율적이고, 중복 탐색과 무한 루프 위험이 줄어든다.
- Anchor↑
- 재귀 CTE의 UNION 위쪽에 위치하는 SELECT 문으로, 재귀의 출발점이 되는 초기 행 집합을 정의한다. 프로그래밍의 반복문에서 초기값 설정(i = 0)에 해당하며, 딱 한 번만 실행된다.

