JVM 메모리 누수 진단과 튜닝
jstat, jmap, 힙 덤프, NMT(Native Memory Tracking)까지 JVM 진단 도구를 활용해 메모리 누수의 원인을 추적하는 방법과, 힙·네이티브·GC JVM 옵션을 운영 환경에 맞게 튜닝하는 방법을 정리합니다.


1편에서 JVM 메모리 구조를, 2편에서 메모리 누수 패턴과 코드 레벨 해결법을 다뤘습니다. 이번 3편에서는 이미 운영 환경에서 문제가 발생했을 때 어떻게 원인을 추적하고 JVM을 튜닝하는지를 실무 도구 중심으로 정리합니다.
| 편 | 내용 | 난이도 |
|---|---|---|
| 1편 | JVM 메모리 구조 — 힙과 네이티브 메모리 | 입문 |
| 2편 | 메모리 누수 패턴과 해결법 | 중급 |
| 3편 (현재) | 메모리 누수 진단과 JVM 튜닝 | 고급 |
증상으로 문제 유형 구분하기
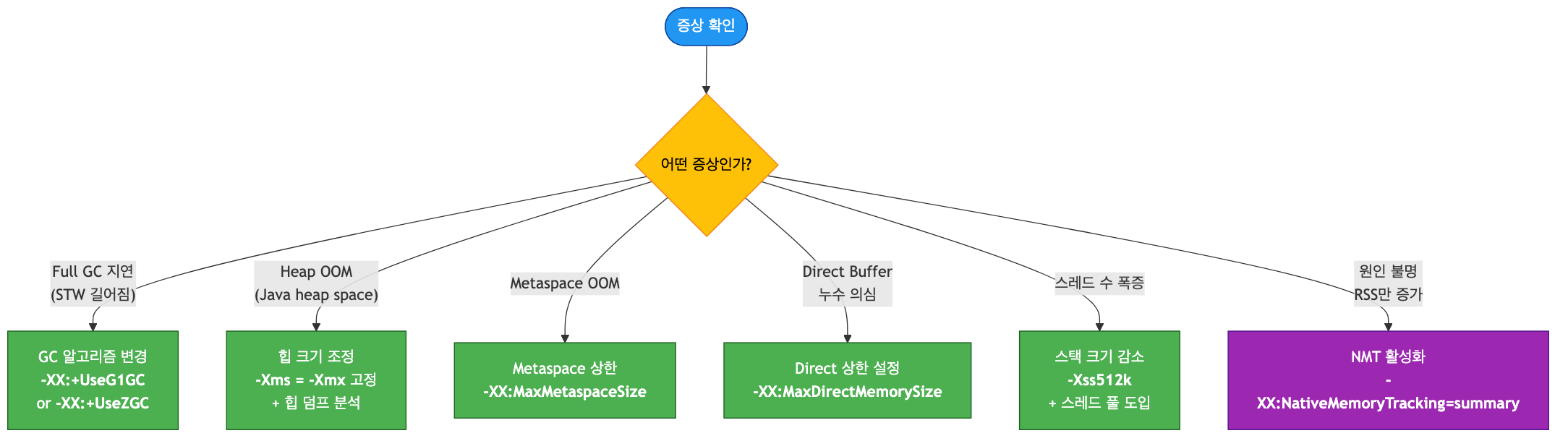
운영 서버의 메모리 문제는 크게 세 가지입니다. 힙 메모리 누수, 네이티브 메모리 누수, 단순한 메모리 부족입니다. 증상은 비슷해 보이지만 진단 경로와 해결법이 완전히 다르므로, 손을 대기 전에 어느 쪽인지부터 구분해야 합니다.
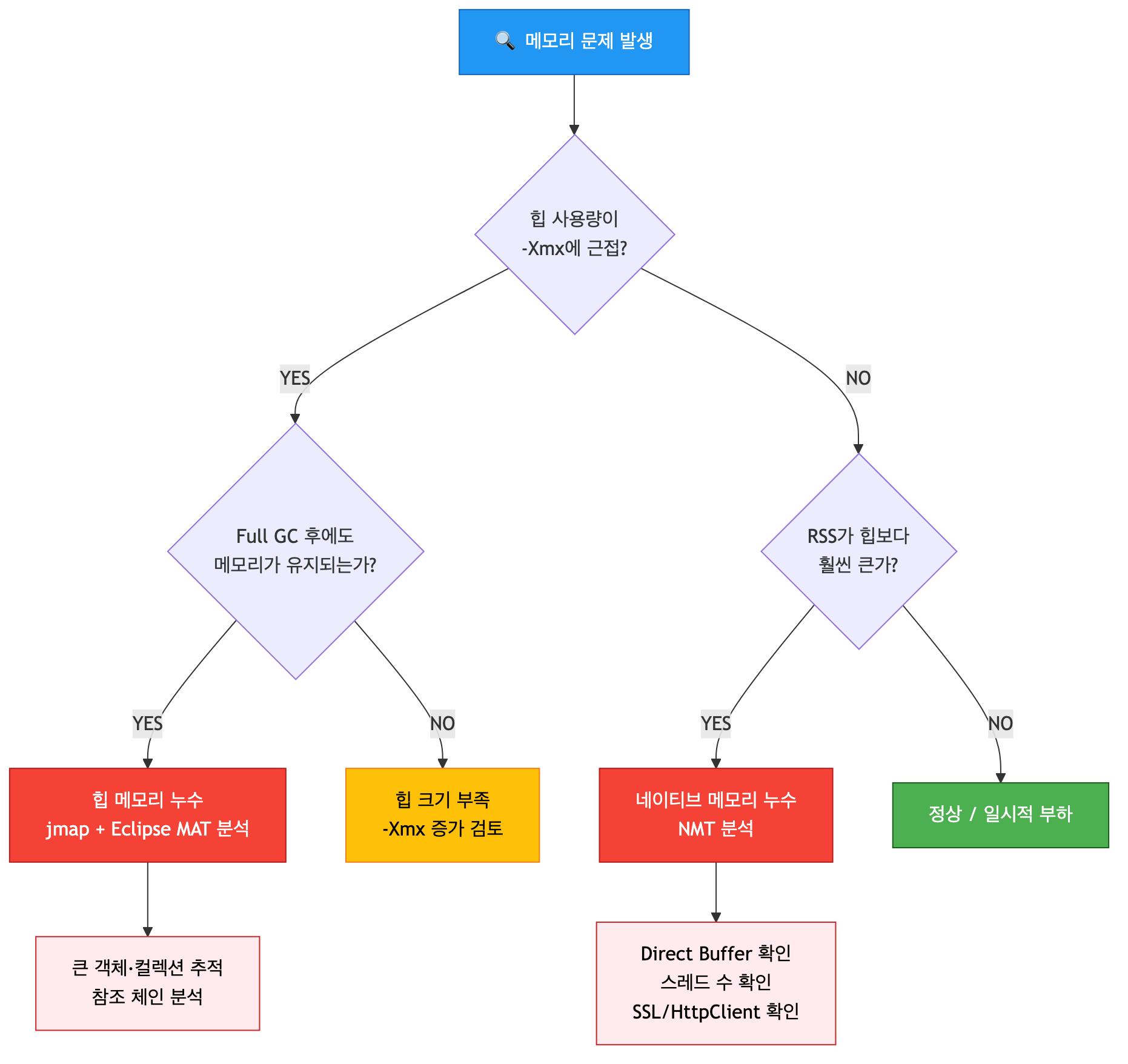
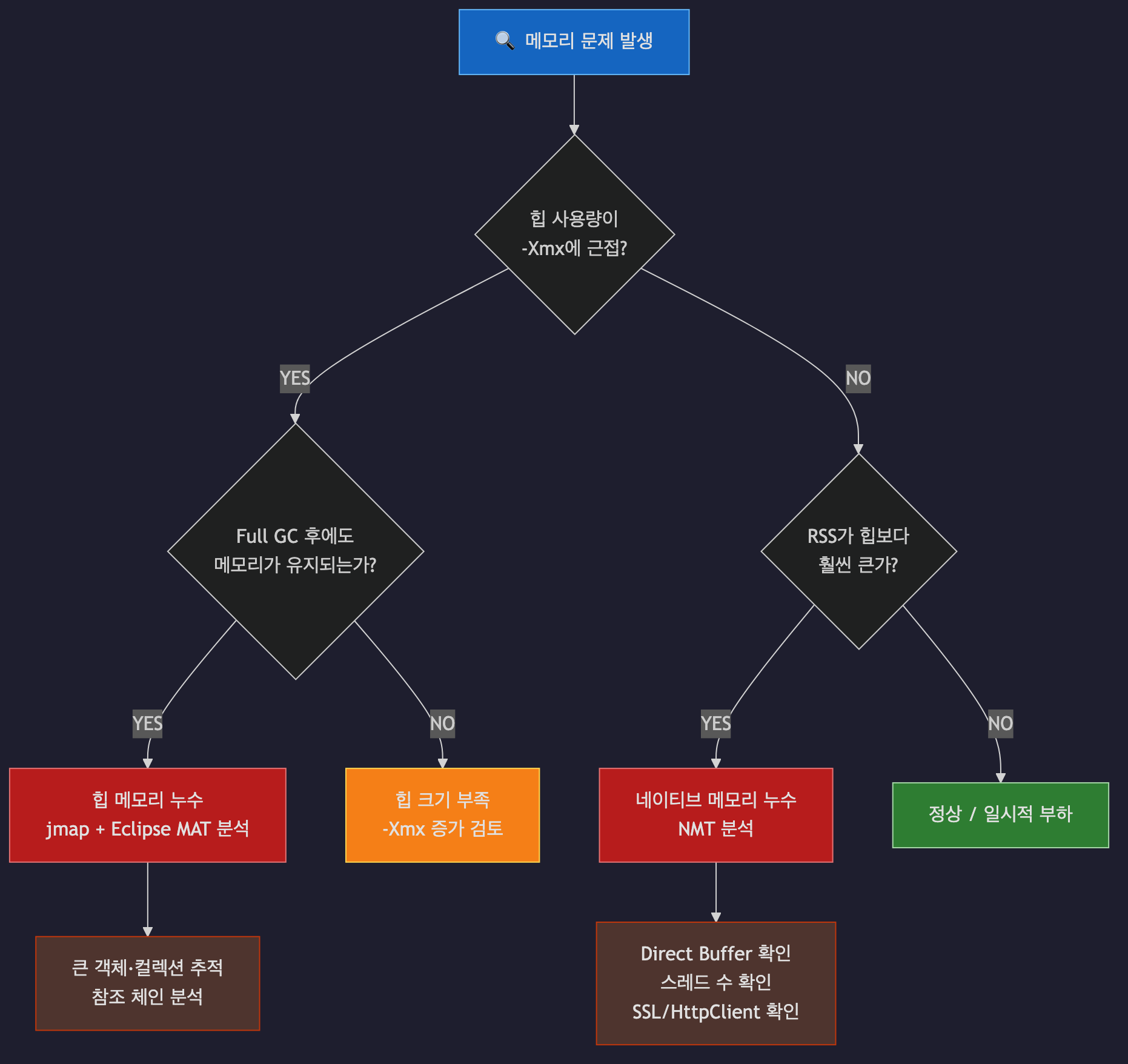
첫 번째 분기: 힙 사용량 확인
힙 사용량이 -Xmx 설정값에 근접해 있다면 힙 문제입니다.
이때 Full GC 직후에도 메모리가 거의 줄지 않는다면 힙 메모리 누수, 일시적으로 확 줄어든다면 힙 크기 부족입니다.
두 번째 분기: RSS와 힙의 괴리
힙 사용량은 멀쩡한데 서버의 실제 메모리(RSS)만 계속 증가한다면 네이티브 메모리 누수입니다.
2편에서 다룬 HttpClient/SslContext 반복 생성, Direct Buffer 미해제, 스레드 누수가 대표적인 원인입니다.
RSS가 힙보다 크다고 무조건 누수는 아닙니다
Metaspace, Code Cache, 스레드 스택, JIT 컴파일러 데이터 등 정상적으로 사용되는 네이티브 영역이 있습니다.
일반적으로 RSS ≈ -Xmx + 500MB ~ 1GB 수준이면 정상 범위로 봅니다.
"RSS가 시간에 따라 단조 증가"하는 패턴이 누수의 핵심 신호입니다.
힙 메모리 진단 도구
힙 문제가 확인됐다면, JDK 진단 도구와 Eclipse MAT을 조합해 원인을 단계적으로 추적합니다.
jstat — 실시간 GC 모니터링
jstat은 애플리케이션을 멈추지 않고 사용할 수 있는 경량 도구로, 운영 서버에 가장 먼저 적용하는 1차 진단 수단입니다.
# 1초 간격으로 GC 상태 출력
jstat -gc <PID> 1000실제 운영 중인 JVM 프로세스에서 캡처한 결과는 다음과 같습니다.

위 화면은 EU가 61440 ~ 65536 사이에서 진동하고 OU가 100878로 고정된 안정 상태입니다.
FGC가 0이라는 것은 Full GC가 한 번도 발생하지 않았다는 뜻이며, 누수 없이 건강하게 동작하는 애플리케이션의 전형적인 모습입니다.
각 컬럼의 의미는 다음과 같습니다.
| 컬럼 | 의미 | 확인 포인트 |
|---|---|---|
EU | Eden 사용량 | Minor GC 시 0에 가깝게 떨어지는가 |
OU | Old 사용량 | 시간에 따라 단조 증가하는가 |
YGC | Young GC 누적 횟수 | 비정상적으로 빈번하지 않은가 |
FGC | Full GC 누적 횟수 | 점점 빈도가 증가하는가 |
FGCT | Full GC 누적 시간(초) | GC 한 번에 얼마나 걸리는가 |
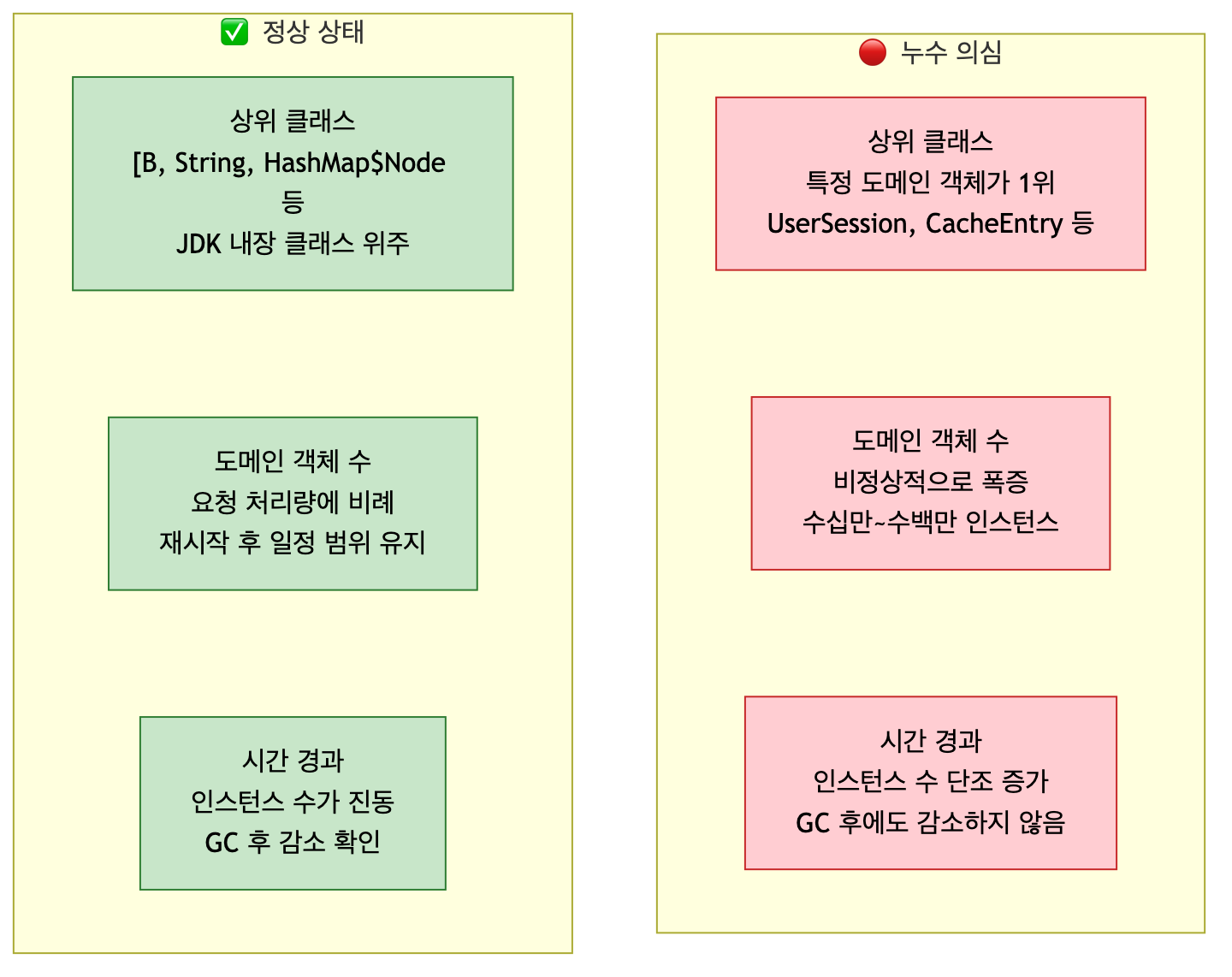
정상 상태와 누수 상태의 jstat 출력은 다음과 같이 다른 패턴을 보입니다.
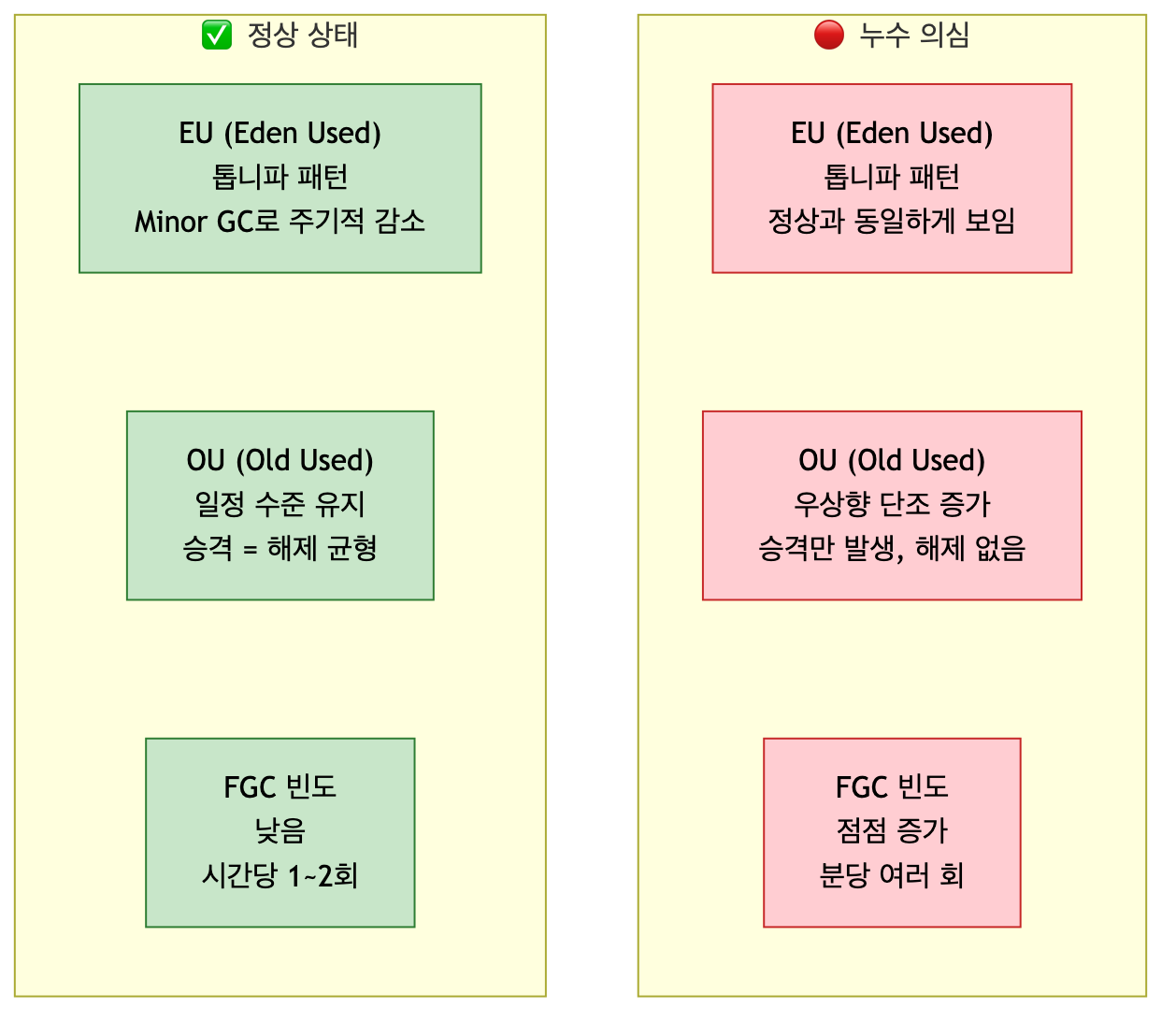

정상 상태의 OU(Old Used)는 승격과 해제가 균형을 이루면서 일정 범위에서 진동합니다.
반면 누수가 있으면 OU가 시간에 따라 단조 증가하고, Old 영역이 가득 차면서 FGC(Full GC) 빈도가 점점 늘어납니다.
jstat -gc PID 1000을 5~10분간 돌린다OU가 단조 증가하면 → 힙 누수 의심 → 힙 덤프 단계로FGC가 분당 여러 번 발생하면 → 즉시 힙 덤프 확보 권장
jmap — 힙 히스토그램과 힙 덤프
jstat으로 누수를 의심하게 됐다면, jmap으로 어떤 클래스가 메모리를 차지하는지 확인합니다.
# 힙 히스토그램 — 상위 30개 클래스의 인스턴스 수와 메모리
jmap -histo:live <PID> | head -30실제 Spring Boot 애플리케이션(Java 17)에서 실행한 결과는 다음과 같습니다.
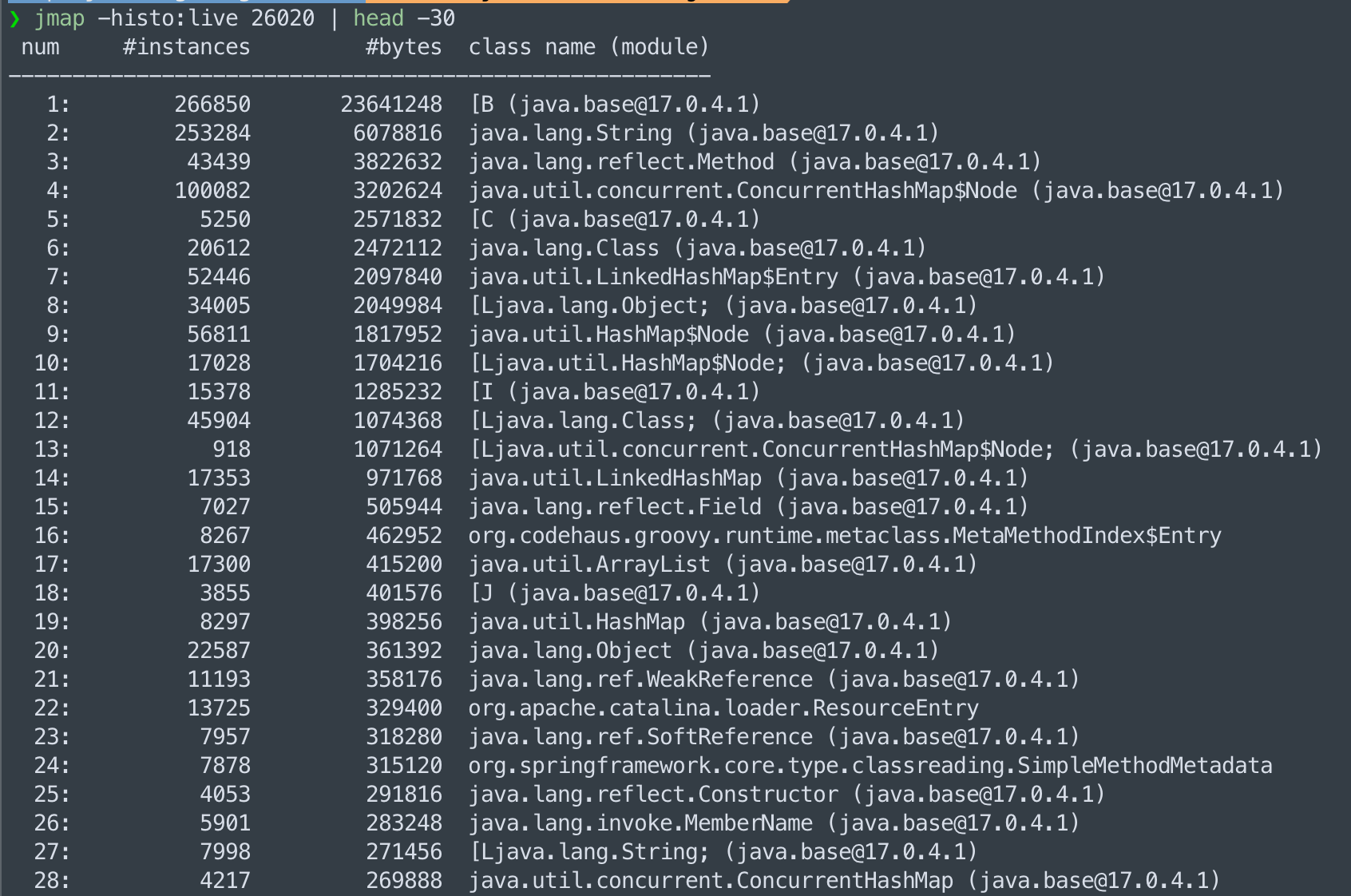
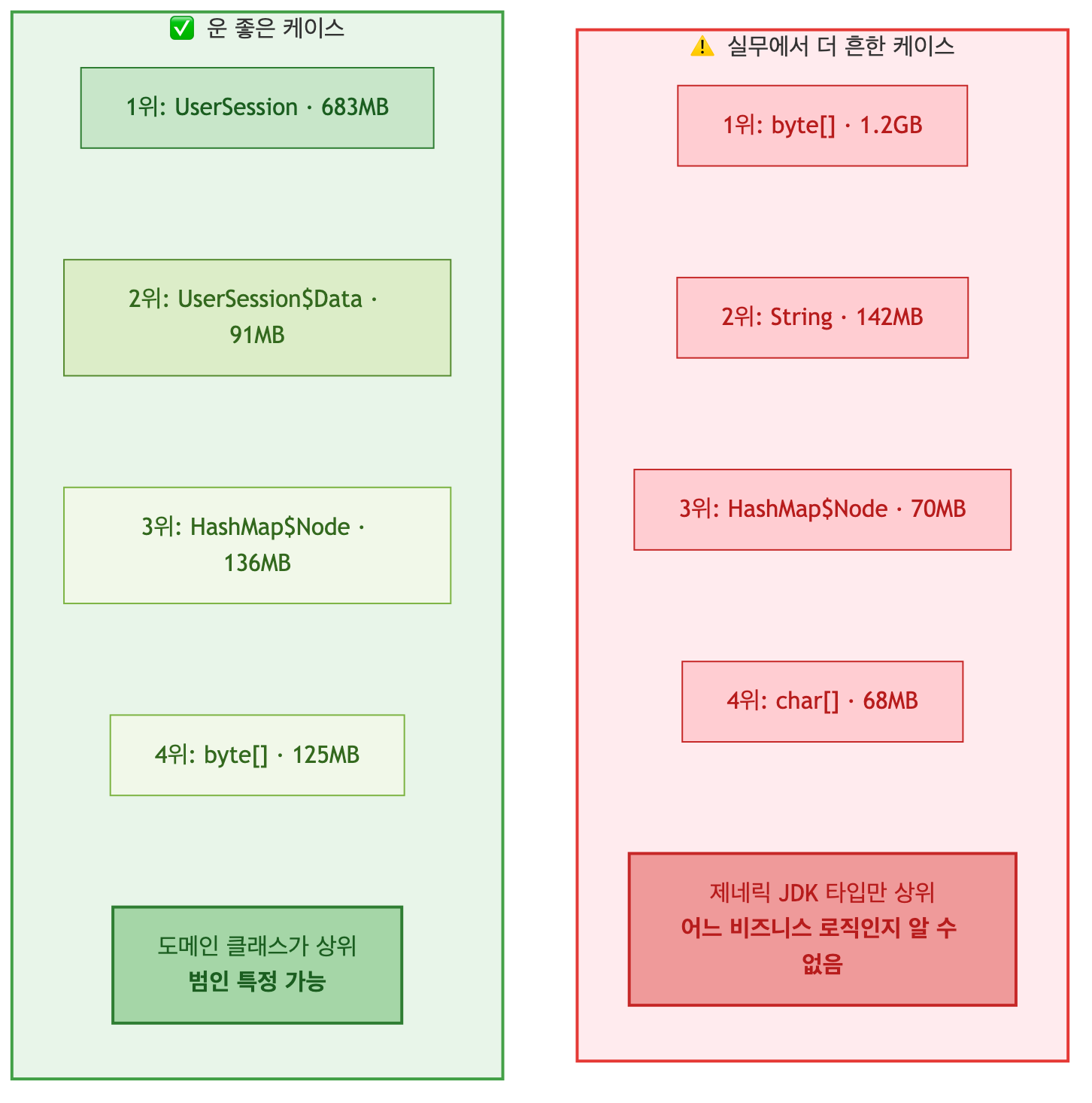
상위를 차지한 것들이 모두 JDK 내장 클래스와 프레임워크 내부 자료구조입니다.
[B(byte[]), String, Method, ConcurrentHashMap$Node, LinkedHashMap$Entry는 대부분의 Spring Boot 애플리케이션에서 공통으로 상위에 등장하는 클래스들입니다.
도메인 객체가 상위 30위 안에 보이지 않는다는 점이 정상 상태의 중요한 신호입니다.
반면 누수가 있는 애플리케이션은 특정 도메인 객체나 그 내부 구성요소가 비정상적으로 상위에 등장합니다.
# 🔴 누수 의심 출력 예시
num #instances #bytes class name
----------------------------------------------
1: 2847563 683415120 com.example.UserSession ← 비정상 폭증
2: 2847563 91122016 com.example.UserSession$Data
3: 5695126 136682008 java.util.HashMap$Node ← UserSession을 담은 Map 엔트리
4: 523456 125629440 [B
5: 45678 1096272 java.lang.String
...UserSession이 수백만 인스턴스로 1위를 차지하고, 이들을 담고 있는 HashMap$Node가 그에 비례해 함께 폭증한 패턴입니다.
전형적인 static 컬렉션에 UserSession을 계속 쌓아두고 제거하지 않는 누수의 시그니처입니다.
정상 상태와 누수 의심 상태를 비교하면 다음 세 가지 포인트에서 차이가 드러납니다.
한 번의 출력만으로는 확실히 판단하기 어려우므로, 시간 간격을 두고 두 번 실행해 증가 추이를 확인하는 것이 중요합니다.
특정 클래스의 #instances가 계속 늘어난다면 해당 클래스가 누수의 주범일 가능성이 높습니다.
# 10분 간격으로 비교
jmap -histo:live <PID> > histo-1.txt
sleep 600
jmap -histo:live <PID> > histo-2.txt
diff histo-1.txt histo-2.txtjmap -histo의 한계 — 제네릭 JDK 타입의 함정
위 UserSession 예시는 운이 좋은 케이스입니다.
도메인 클래스가 상위에 직접 등장해줬기 때문에 jmap -histo만으로도 범인을 특정할 수 있었습니다.
하지만 실무에서는 그렇지 않은 경우가 훨씬 많습니다.
누수 객체가 byte[], char[], String, HashMap$Node 같은 제네릭 JDK 타입으로 드러나는 상황입니다.
이들은 정상 애플리케이션에서도 항상 상위권을 차지하기 때문에, 단순히 상위에 있다는 사실만으로는 누수의 원인을 알 수 없습니다.

예를 들어 byte[]가 1.2GB로 1위라면 다음 질문들에 답할 수 없습니다.
| 질문 | jmap -histo로 답할 수 있는가 |
|---|---|
byte[]가 총 몇 개, 몇 MB인가? | ✅ 가능 |
그 byte[]를 누가 생성했는가? (이미지 캐시? HTTP 버퍼? JDBC 결과?) | ❌ 불가능 |
어떤 객체가 그 byte[]를 참조로 붙잡고 있는가? | ❌ 불가능 |
| 어느 GC Root에서 도달 가능한가? | ❌ 불가능 |
jmap -histo는 "무엇이 많은가"는 알려주지만 "어디서 만들었는가, 누가 붙잡고 있는가"는 알려주지 않습니다.
원인을 규명하려면 힙 덤프를 떠서 참조 체인(reference chain) 을 역추적해야 합니다.
여기서부터 Eclipse MAT 같은 전문 분석 도구가 필요해집니다.
도구의 위계로 정리하면
jstat → 이상 신호 탐지 (OU 단조 증가, Full GC 빈도)
jmap -histo → 1차 스크리닝 (어떤 타입이 비정상적으로 많은가)
힙 덤프 + MAT → 2차 정밀 분석 (누가 붙잡고 있는가)
운 좋게 1차에서 도메인 클래스가 보이면 거기서 멈출 수 있지만, 제네릭 타입이 상위라면 2차까지 반드시 가야 합니다.
힙 덤프 + MAT으로 참조 체인 역추적
참조 체인을 분석하려면 먼저 전체 힙의 스냅샷이 필요합니다.
# 힙 덤프 생성 — .hprof 파일로 전체 힙 스냅샷 저장
jmap -dump:live,format=b,file=/tmp/heap.hprof <PID>운영 서버에서 힙 덤프를 뜰 때 주의점
jmap -dump은 덤프가 완료될 때까지 JVM을 일시 정지시킵니다.
수 GB 힙의 경우 수 초~수십 초의 멈춤이 발생하므로, 트래픽을 끊고 실행하거나 레플리카에서 수행해야 합니다.
또한 .hprof 파일에는 모든 객체 데이터가 들어있어 민감 정보가 포함될 수 있습니다. 외부에 공유할 때 반드시 점검하세요.
생성된 .hprof 파일을 Eclipse MAT(Memory Analyzer Tool) 로 열면 Leak Suspects 리포트가 자동 생성됩니다.
MAT이 휴리스틱으로 "이 객체가 의심됩니다"를 1차 제안하는 리포트로, 대부분의 명백한 누수는 여기서 바로 드러납니다.
다만 자동 리포트가 늘 정확한 것은 아니므로, Dominator Tree와 Path to GC Roots를 직접 읽을 줄 알아야 합니다.
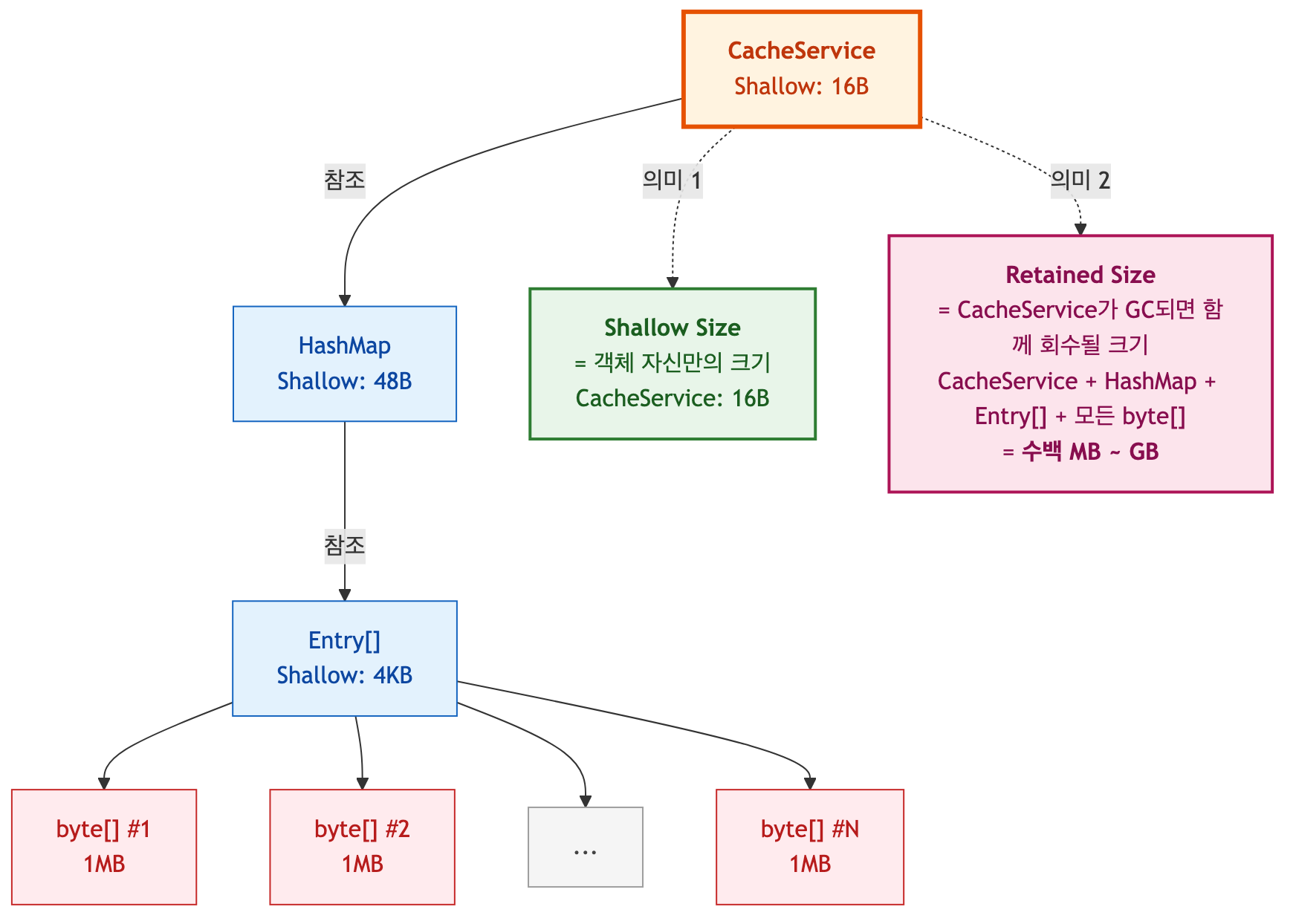
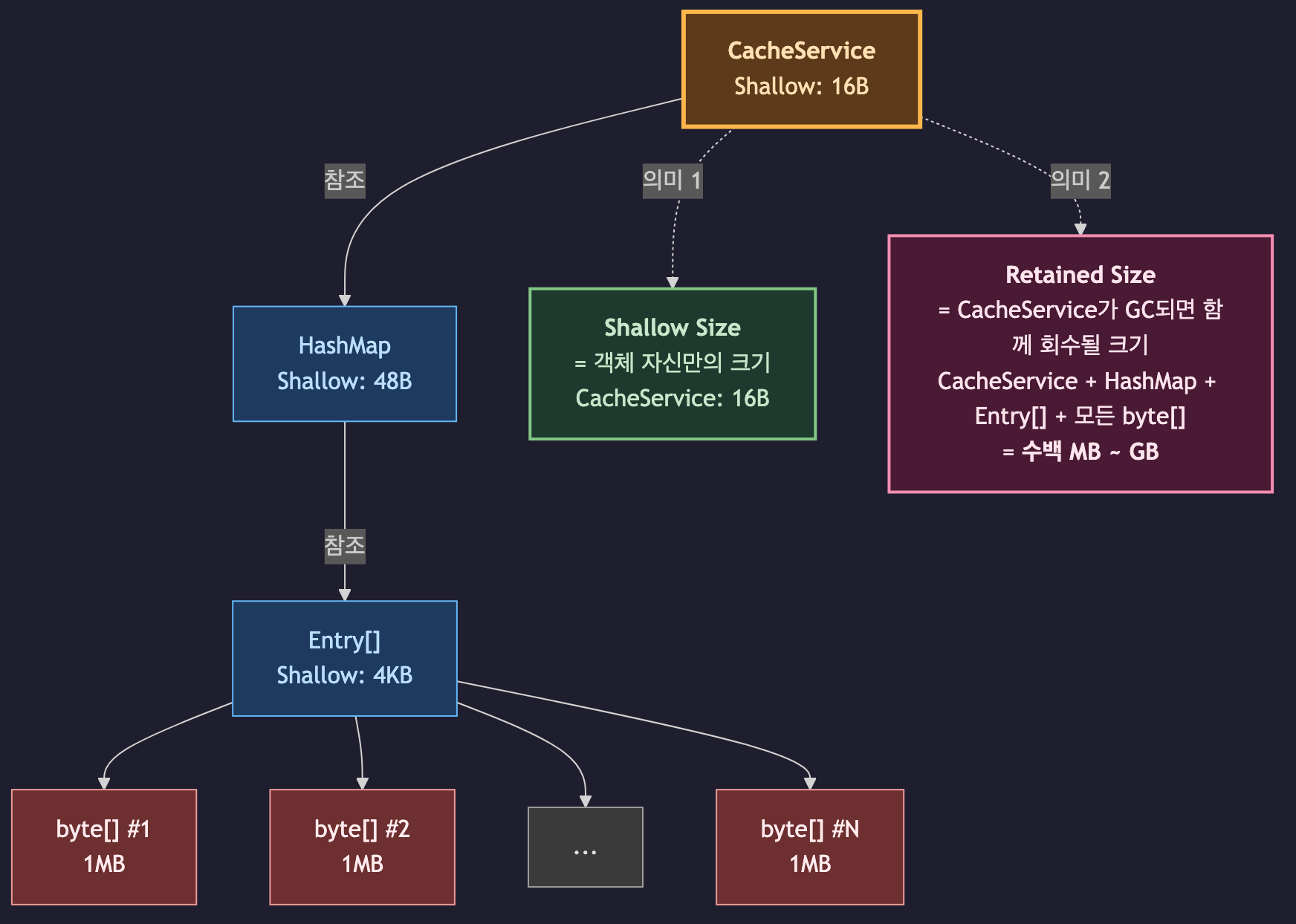
Shallow Size vs Retained Size
MAT을 제대로 읽으려면 두 가지 크기 개념을 먼저 이해해야 합니다.
| 개념 | 의미 | 예시 |
|---|---|---|
| Shallow Size | 객체 자신이 차지하는 메모리 | HashMap 인스턴스: 약 48B |
| Retained Size | 이 객체가 GC되면 함께 회수될 메모리의 총합 | HashMap + 내부 Entry[] + 모든 엔트리의 값: 수백 MB |
누수 분석에서 Shallow Size를 보는 것은 거의 의미가 없습니다.
HashMap 인스턴스 자체는 수십 바이트에 불과하지만, 그 안에 1GB짜리 byte[]를 담고 있다면 진짜 범인은 이 HashMap입니다.
항상 Retained Size 내림차순으로 정렬해야 진짜 메모리를 붙잡고 있는 객체를 찾을 수 있습니다.
Dominator Tree — 진짜 범인 찾기
Dominator Tree는 MAT의 가장 중요한 뷰입니다. 일반 참조 그래프는 한 객체가 여러 부모를 가질 수 있어 복잡하지만, Dominator Tree는 객체마다 단일 부모(dominator)로 단순화되어 "누가 단독으로 이 메모리를 붙잡고 있는가"를 한눈에 보여줍니다.
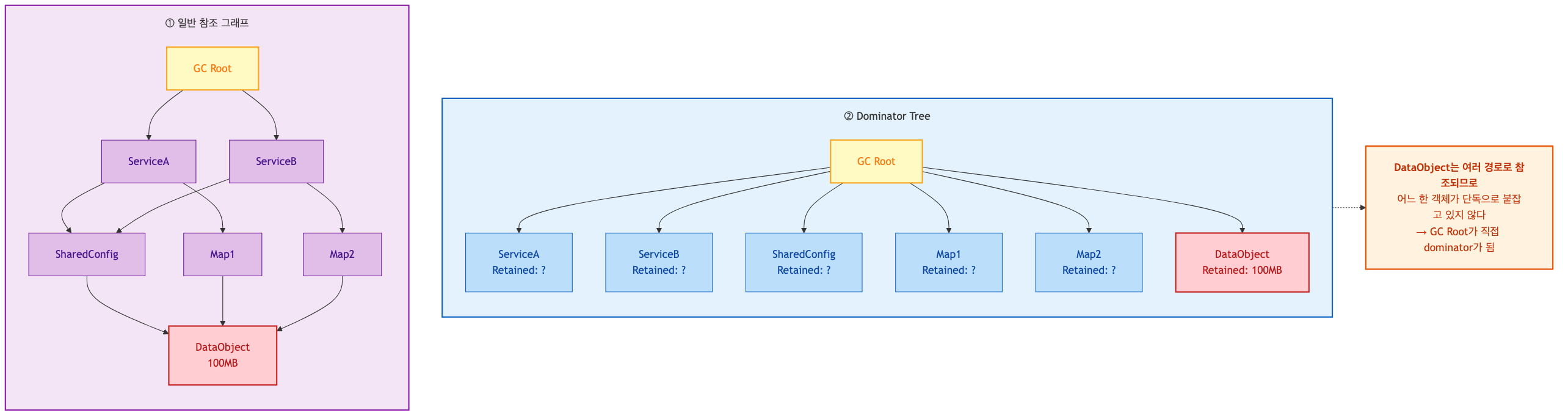
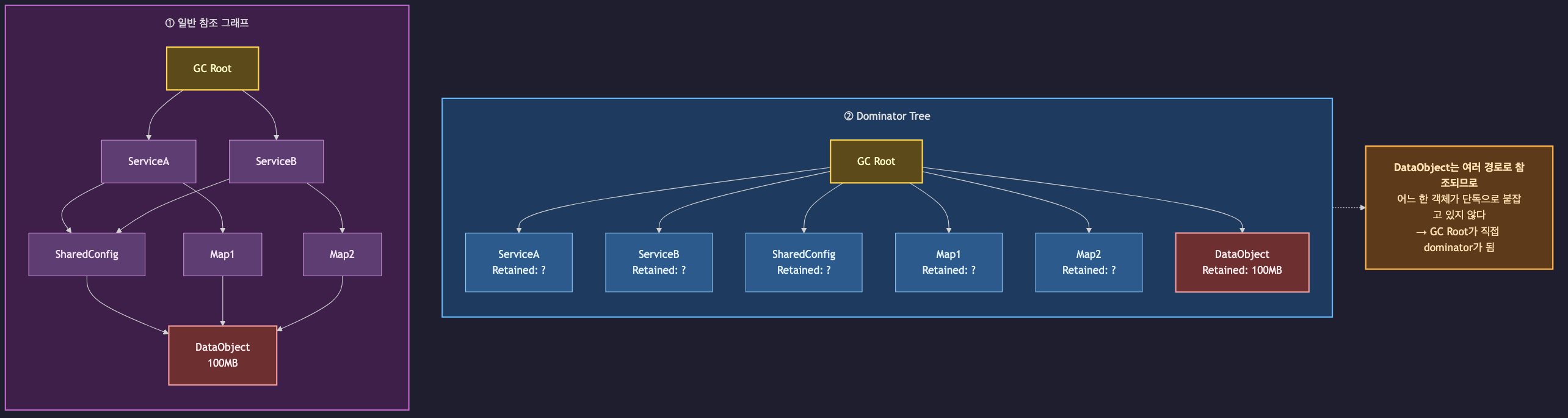
"X의 dominator는 Y"의 정확한 정의는 "Y를 제거하면 X가 반드시 GC 대상이 된다" 입니다. 즉 Y는 X를 단독으로 지배(dominate)하는 유일한 경로입니다. 이 관계로 트리를 만들면, 트리의 최상단에서 시작해 Retained Size가 비정상적으로 큰 노드를 따라 내려가는 것만으로도 누수의 중심지까지 닿을 수 있습니다.
- Retained Size 내림차순으로 정렬
- 최상단에서 도메인 클래스(
com.example.*)를 먼저 찾는다 - 프레임워크/JDK 클래스밖에 안 보이면 그 노드를 펼쳐 하위로 내려가며 탐색
- 비정상적으로 큰 Retained Size를 가진 노드가 누수의 중심지
Path to GC Roots — 누수 경로 역추적
Dominator Tree로 "무엇이 많이 붙잡고 있는가" 를 찾았다면, 다음은 "왜 GC되지 않는가" 를 확인할 차례입니다. 의심 객체에서 시작해 거꾸로 GC Root까지 거슬러 올라가는 경로를 찾는 기능이 Path to GC Roots입니다.
![byte[]에서 GC Root까지의 참조 체인 역추적](/images/posts/jvm-memory-diagnosis-tuning/path-to-gc-roots-light.png)
![byte[]에서 GC Root까지의 참조 체인 역추적](/images/posts/jvm-memory-diagnosis-tuning/path-to-gc-roots-dark.png)
GC Root의 종류와 각각이 가리키는 누수 패턴은 다음과 같습니다.
| GC Root 종류 | 의미 | 대표적 누수 원인 |
|---|---|---|
| System Class | static 필드가 참조하는 객체 | static Map / 싱글톤 캐시가 무한정 축적 |
| Thread | 활성 스레드의 로컬 변수·ThreadLocal | ThreadLocal.remove() 누락, 스레드 풀에서 데이터 잔존 |
| Busy Monitor | 동기화 락 보유 객체 | 락 대기 중인 스레드 누적 |
| JNI Global | 네이티브 코드의 전역 참조 | JNI 라이브러리의 참조 해제 누락 |
| Java Local | 현재 실행 중인 메서드의 스택 | 일시적. 보통 누수 원인 아님 |
MAT에서 "Exclude weak/soft references" 옵션을 켜고 Path to GC Roots를 실행하는 것이 핵심입니다. 약한 참조(WeakReference/SoftReference)는 GC의 재량이라 누수의 원인이 될 수 없기 때문입니다. 이 옵션 없이 실행하면 수많은 약한 참조 경로에 파묻혀 진짜 강한 참조 경로를 놓치기 쉽습니다.
실무 워크플로우 — byte[] 1위에서 static Map까지
여기까지의 개념을 실제 시나리오로 꿰어보겠습니다. 이미지 캐시 서비스에서 메모리 누수가 의심되는 상황을 가정합니다.
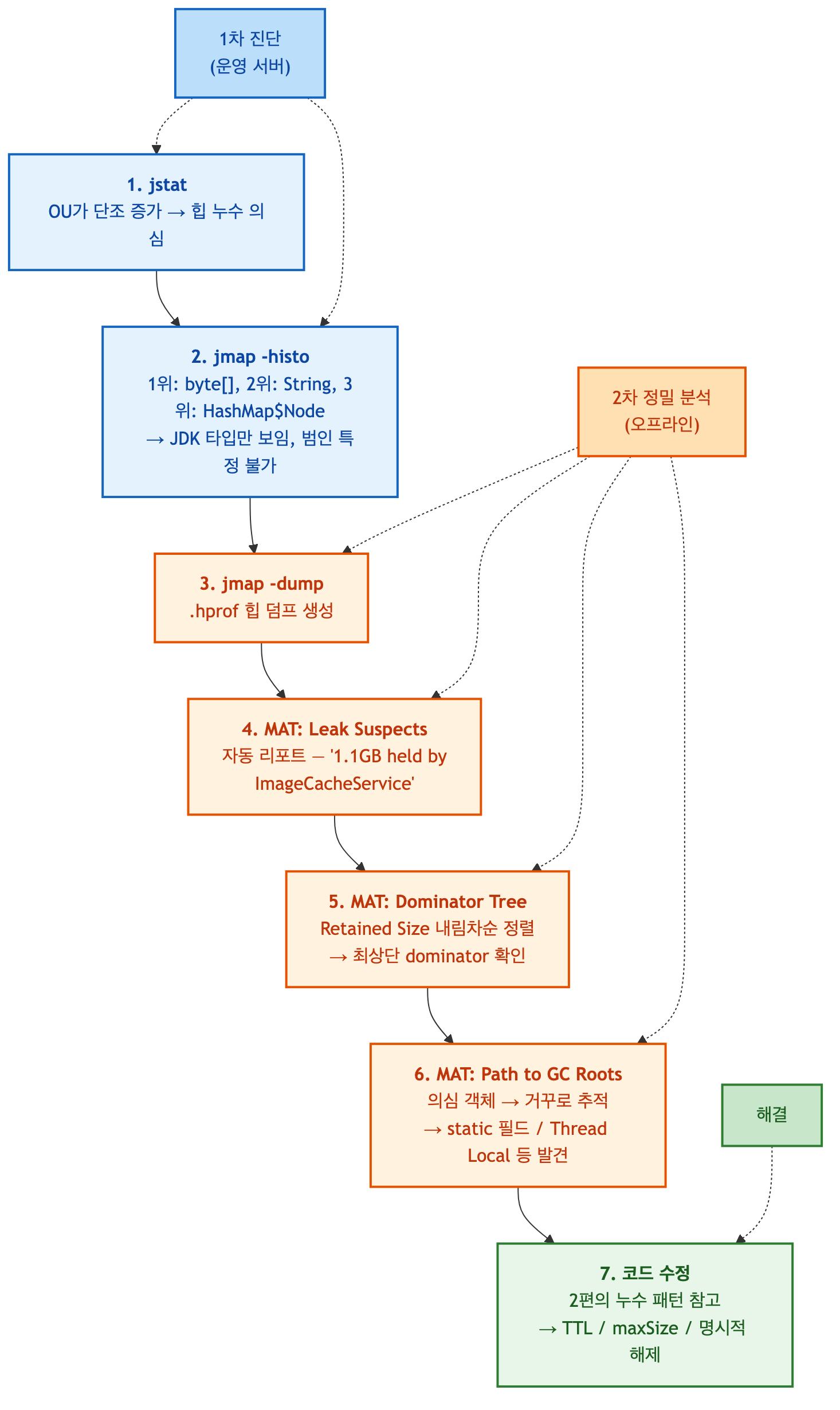
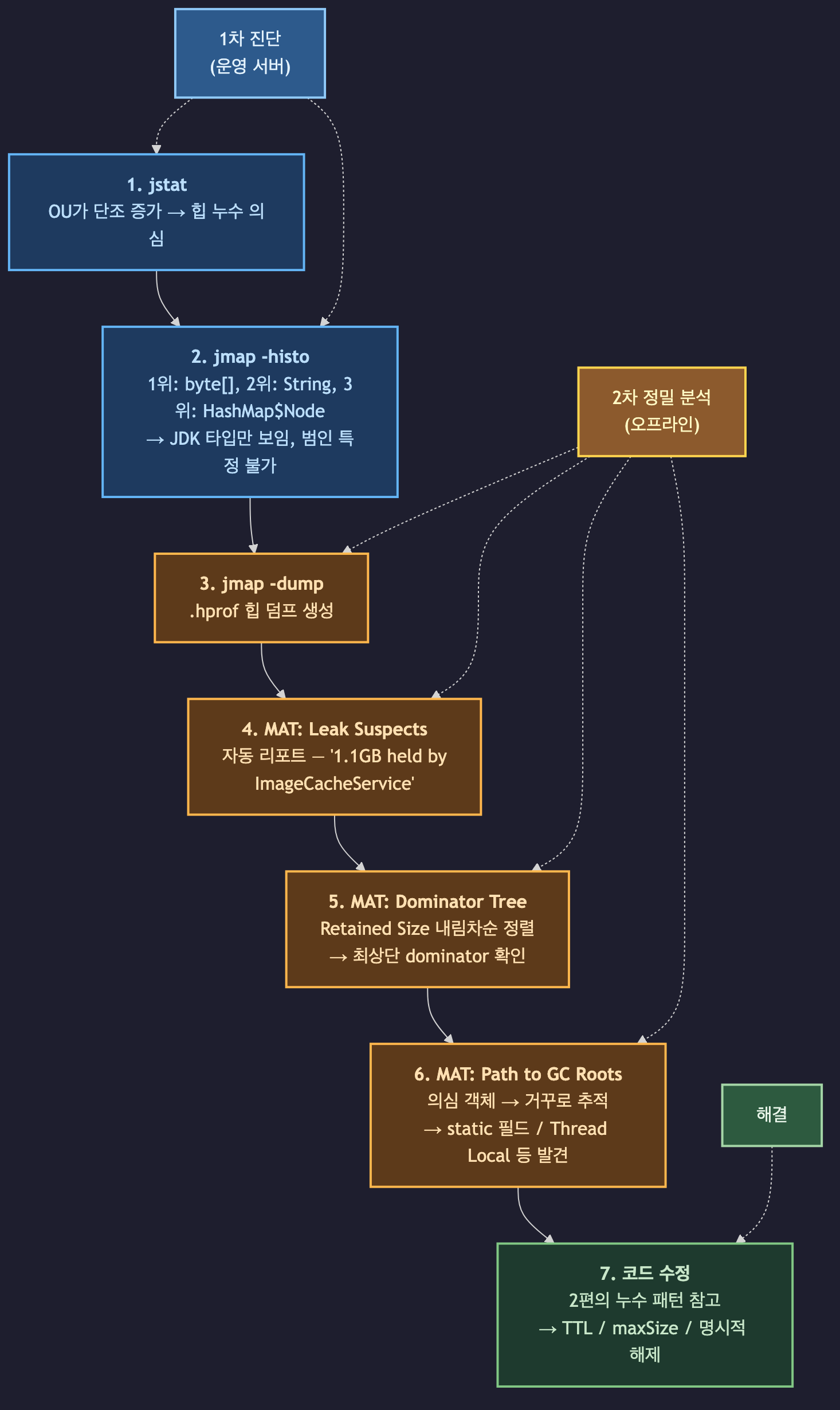
단계별 사고 과정은 다음과 같습니다.
1단계 — 이상 감지 (jstat)
운영 서버에서 jstat -gc <PID> 1000을 5분간 관찰하니 OU가 단조 증가하고 FGC가 분당 2~3회 발생합니다.
힙 누수가 확실합니다.
2단계 — 1차 스크리닝 (jmap -histo)
jmap -histo:live <PID> | head -10의 상위에는 [B(byte[]) 1.2GB, String 142MB, HashMap$Node 70MB가 올라왔습니다.
전부 JDK 타입입니다. 어떤 비즈니스 로직이 이 byte[] 1.2GB를 만들었는지 알 수 없습니다.
3단계 — 힙 덤프 확보 (jmap -dump) 레플리카 서버에서 트래픽을 뺀 뒤 힙 덤프를 생성합니다.
jmap -dump:live,format=b,file=/tmp/heap.hprof <PID>4단계 — MAT Leak Suspects
생성된 .hprof를 MAT으로 열면 Leak Suspects 리포트가 자동 뜹니다.
"Problem Suspect 1: 1.1 GB held by com.example.ImageCacheService"라는 메시지가 나옵니다.
자동 리포트지만 대부분 이 시점에 범인의 정체가 드러납니다.
5단계 — Dominator Tree로 확정
"의심만으로는 불안하니 직접 확인하자" — Dominator Tree를 Retained Size 내림차순으로 정렬합니다.
최상단에 ImageCacheService 인스턴스가 1.1GB를 보유한 것이 확인됩니다.
펼쳐보니 내부 ConcurrentHashMap이 수만 개의 byte[] 엔트리를 담고 있습니다.
6단계 — Path to GC Roots로 원죄 추적
ImageCacheService 인스턴스에서 우클릭 → "Path to GC Roots" → "exclude weak/soft references"를 실행합니다.
경로가 나옵니다 — ImageCacheService 인스턴스 → ImageCacheService.INSTANCE static 필드 → <System Class> GC Root.
static 싱글톤 캐시가 TTL 없이 무한정 쌓이는 것이 원인입니다.
7단계 — 코드 수정
2편에서 다룬 "static 컬렉션 누수" 패턴과 정확히 일치합니다.
ConcurrentHashMap을 Caffeine/Guava 캐시로 교체하고 maximumSize와 expireAfterWrite를 설정해 해결합니다.
이 흐름의 핵심은 각 도구를 단독이 아니라 위계로 쌓아서 쓰는 것입니다.
jstat이 이상을 잡고, jmap -histo가 범위를 좁히고, MAT의 Dominator Tree가 중심지를 찾고, Path to GC Roots가 원죄를 지목합니다.
어느 한 단계에서 멈추면 "byte[]가 많다"까지만 알고 끝납니다.
OOM 발생 시 자동 덤프 설정
사전에 JVM 옵션을 켜두면 OutOfMemoryError 발생 시 자동으로 힙 덤프를 남깁니다.
장애 발생 후 상태를 보존할 수 있는 가장 중요한 운영 설정입니다.
java \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/var/log/app/heapdump.hprof \
-jar app.jar이 옵션은 운영 환경의 필수 설정입니다
OOM으로 프로세스가 재시작되면 원인 분석이 어렵습니다.
덤프 파일이 남아있어야 사후 분석이 가능하므로, 모든 Java 운영 서버에서 기본으로 켜두는 것을 권장합니다.
네이티브 메모리 진단 도구
네이티브 메모리 누수는 힙 덤프에 나타나지 않습니다. 별도의 진단 도구와 접근법이 필요합니다.
NMT — 네이티브 메모리 카테고리별 추적
NMT(Native Memory Tracking)는 JVM 내부에서 사용하는 네이티브 메모리를 카테고리별로 기록하는 기능입니다. 기본적으로 비활성화되어 있으므로 JVM 옵션으로 켜야 합니다.
# NMT 활성화 — summary 또는 detail 모드
java -XX:NativeMemoryTracking=summary -jar app.jar
# 실행 중인 프로세스에서 리포트 조회
jcmd <PID> VM.native_memory summary출력은 영역별 예약(reserved)과 실제 사용(committed) 메모리를 보여줍니다.
Native Memory Tracking:
Total: reserved=2500MB, committed=800MB
- Java Heap (reserved=512MB, committed=512MB)
- Class (reserved=120MB, committed=25MB)
- Thread (reserved=150MB, committed=150MB)
- Code (reserved=250MB, committed=48MB)
- GC (reserved=85MB, committed=72MB)
- Compiler (reserved=8MB, committed=8MB)
- Internal (reserved=64MB, committed=64MB)
- Symbol (reserved=32MB, committed=32MB)
- Native Memory Tracking (reserved=12MB, committed=12MB)각 카테고리의 의미는 다음과 같습니다.


| 카테고리 | 포함 내용 | 누수 의심 시 확인 |
|---|---|---|
| Java Heap | -Xmx로 설정한 힙 영역 | 이미 힙 진단으로 확인 |
| Thread | 스레드 스택 (스레드 수 × -Xss) | 시간에 따라 계속 증가하는가 |
| Class | Metaspace, 클래스 메타데이터 | 클래스 리로드가 과도하지 않은가 |
| Code | JIT 컴파일된 기계어 코드 | 보통 수십~수백 MB로 안정적 |
| GC | GC 알고리즘 내부 자료구조 | 힙 크기에 비례 |
| Internal | Direct ByteBuffer, NIO 버퍼 | Direct Buffer 누수 의심 |
| Symbol | 심볼 테이블, 문자열 상수 풀 | 보통 변동 적음 |
NMT는 모든 네이티브 메모리를 보여주지 않습니다
NMT는 JVM이 직접 할당한 네이티브 메모리만 추적합니다.
JNI 라이브러리(OpenSSL, Netty, OpenCV 등)가 내부에서 malloc으로 할당한 메모리는 NMT에 보이지 않습니다.
그럼에도 RSS가 계속 증가한다면 NMT로 보이지 않는 네이티브 라이브러리의 누수를 의심해야 합니다.
기준선 비교로 증가분 추적
NMT의 진짜 강점은 기준선(baseline)과의 비교입니다. 시작 시점 또는 특정 시점의 스냅샷을 찍어두고, 이후 증가분만 비교할 수 있습니다.
# 현재 상태를 기준선으로 저장
jcmd <PID> VM.native_memory baseline
# 일정 시간 후 증가분 확인
jcmd <PID> VM.native_memory summary.diffsummary.diff 출력에서 + 표시된 영역이 증가분입니다.
예를 들어 Thread가 +50MB 늘었다면 스레드가 새로 50개(기본 -Xss=1m 기준) 생성됐다는 뜻입니다.
OS 레벨 — RSS로 전체 확인
NMT에 잡히지 않는 네이티브 라이브러리 누수까지 확인하려면 OS 레벨 도구가 필요합니다.
# 현재 RSS 확인 (KB 단위)
ps -o pid,rss,vsz -p <PID>
# 주기적 관찰 — 5초 간격으로 RSS 변화 추적
while true; do
date
ps -o pid,rss -p <PID> | tail -1
sleep 5
doneRSS 값이 시간에 따라 단조 증가한다면 네이티브 메모리 누수가 확실합니다.
NMT 출력의 Total committed 값과 비교해서, RSS - NMT Total이 크게 벌어진다면 JNI 라이브러리 영역의 누수를 의심합니다.
JVM 튜닝 옵션
진단으로 원인을 찾았다면, 그다음은 JVM 옵션을 상황에 맞게 조정하는 단계입니다.
힙 메모리 옵션
| 옵션 | 설명 | 권장값 |
|---|---|---|
-Xms | 초기 힙 크기 | -Xmx와 동일 |
-Xmx | 최대 힙 크기 | 물리 메모리의 50~70% |
-XX:NewRatio | Old:Young 비율 | 기본 2 (대부분 수정 불필요) |
-XX:SurvivorRatio | Eden:Survivor 비율 | 기본 8 (대부분 수정 불필요) |
가장 중요한 원칙은 -Xms와 -Xmx를 동일하게 설정하는 것입니다.
두 값이 다르면 JVM이 부하 상황에서 힙을 확장/축소하는 오버헤드가 발생합니다.
운영 환경에서는 고정 크기가 예측 가능성 면에서 유리합니다.
# ✅ 권장: 힙 크기 고정
java -Xms2g -Xmx2g -jar app.jar
# ❌ 비권장: 힙 크기 동적 변경
java -Xms512m -Xmx2g -jar app.jar네이티브 메모리 옵션
| 옵션 | 설명 | 권장값 |
|---|---|---|
-XX:MaxDirectMemorySize | Direct ByteBuffer 상한 | -Xmx의 25~50% |
-XX:MaxMetaspaceSize | Metaspace 상한 | 256m~512m |
-Xss | 스레드 스택 크기 | 512k (기본 1m에서 절반) |
RSS 관리의 핵심은 상한을 명시적으로 설정하는 것입니다.
기본값은 MaxDirectMemorySize가 -Xmx와 동일하고, MaxMetaspaceSize는 무제한입니다.
이 상태로는 네이티브 메모리가 무한정 늘어날 수 있으므로, 실측에 기반해 상한을 지정해야 합니다.
java \
-Xmx2g \
-XX:MaxDirectMemorySize=512m \
-XX:MaxMetaspaceSize=256m \
-Xss512k \
-jar app.jarGC 알고리즘 선택
| GC | Java 버전 | 특징 | 적합한 상황 |
|---|---|---|---|
| G1GC | Java 9+ 기본 | 힙을 Region으로 분할, 일시 정지 목표 설정 가능 | 대부분의 서비스 (범용) |
| ZGC | Java 15+ 정식 | ms 단위 일시 정지, 대용량 힙 지원 | 저지연 요구 (금융, 실시간) |
| Shenandoah | Java 12+ | ZGC와 유사, 낮은 지연 | 대용량 힙, 비OpenJDK |
| Parallel GC | Java 8 기본 | 높은 처리량 지향 | 배치 작업, 응답성보다 throughput |
G1GC는 Java 9부터 기본값이므로 따로 지정하지 않아도 됩니다. 응답 시간이 중요하고 힙이 10GB 이상이라면 ZGC 적용을 고려합니다.
# G1GC — 최대 일시 정지 목표 200ms
java -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -jar app.jar
# ZGC — 대용량 힙, 저지연
java -XX:+UseZGC -Xmx16g -jar app.jarGC 튜닝은 마지막 수단입니다
대부분의 메모리 문제는 GC 알고리즘이 아니라 코드의 누수에서 옵니다.
GC 옵션을 바꾸기 전에 Stop-The-World 시간과 빈도부터 측정하고, 정말로 GC가 병목인지 확인해야 합니다.
누수가 있는 애플리케이션에서 GC 알고리즘만 바꾸면 문제를 숨길 뿐 해결되지 않습니다.
운영 환경 권장 설정
앞선 옵션들을 종합한 실무 운영 설정 예시입니다. 이 설정을 기본 템플릿으로 두고, 서비스 특성에 맞춰 조정하는 것을 권장합니다.
java \
-Xms2g -Xmx2g \
-XX:MaxDirectMemorySize=512m \
-XX:MaxMetaspaceSize=256m \
-Xss512k \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/var/log/app/heapdump.hprof \
-XX:+ExitOnOutOfMemoryError \
-XX:NativeMemoryTracking=summary \
-Xlog:gc*:file=/var/log/app/gc.log:time,uptime:filecount=10,filesize=10M \
-jar app.jar옵션을 그룹별로 나눠 보면 목적이 명확해집니다.
| 그룹 | 옵션 | 목적 |
|---|---|---|
| 힙 메모리 | -Xms, -Xmx | 고정 크기로 예측 가능한 메모리 사용 |
| 네이티브 메모리 상한 | MaxDirectMemorySize, MaxMetaspaceSize, -Xss | RSS 무제한 증가 방지 |
| GC | UseG1GC, MaxGCPauseMillis | 범용 서비스에 적합한 G1GC + 응답시간 목표 |
| 장애 대응 | HeapDumpOnOutOfMemoryError, ExitOnOutOfMemoryError | OOM 시 자동 덤프, 프로세스 즉시 종료(재시작 위임) |
| 진단 | NativeMemoryTracking, -Xlog:gc* | NMT 상시 활성화, GC 로그 로테이션 |
ExitOnOutOfMemoryError가 필요한 이유
OOM이 발생한 JVM은 내부 상태가 불안정합니다.
프로세스를 계속 실행하면 일부 요청은 성공하고 일부는 실패하는 애매한 상태가 지속됩니다.
컨테이너 환경에서는 즉시 종료 → 재시작이 가장 안전한 대응이며, 쿠버네티스·ECS 등의 헬스체크가 이를 감지해 자동 복구합니다.
실무 체크리스트
운영 배포 전 확인
-Xms와-Xmx가 동일한 값으로 설정되어 있는가?-XX:MaxDirectMemorySize,-XX:MaxMetaspaceSize로 네이티브 상한을 지정했는가?-XX:+HeapDumpOnOutOfMemoryError+HeapDumpPath가 설정되어 있는가?- GC 로그가 파일로 남고 로테이션되고 있는가?
- 컨테이너의 메모리 리밋이
-Xmx + 네이티브 여유분이상으로 잡혀 있는가?
운영 중 모니터링
- 힙 사용량(
used / max)을 시계열로 수집하고 있는가? - Old Generation 사용량이 시간에 따라 단조 증가하지 않는가?
- Full GC 빈도가 비정상적으로 높지 않은가?
- RSS 메모리가 시간에 따라 단조 증가하지 않는가?
- 스레드 수가 일정 범위 안에서 유지되는가?
장애 발생 시
- 1차 진단:
jstat -gc PID 1000으로 GC 패턴 확인 - 2차 스크리닝:
jmap -histo로 상위 클래스 확인 (도메인 타입 유무 파악) - 정밀 분석: 힙 덤프(
jmap -dump) + MAT의 Dominator Tree / Path to GC Roots로 원인 역추적 - 네이티브 분석:
jcmd PID VM.native_memory summary.diff로 증가 영역 확인 - OS 레벨:
ps -o rss로 RSS 추이 확인 - 코드 수정: 2편의 누수 패턴을 참고해 원인 제거
시리즈를 마치며
세 편에 걸쳐 JVM 메모리를 다뤘습니다.
| 편 | 핵심 내용 |
|---|---|
| 1편 | JVM이 메모리를 힙과 네이티브로 나눠 관리하는 구조 |
| 2편 | 실무에서 만나는 7가지 메모리 누수 패턴과 해결 코드 |
| 3편 | 운영 환경에서 진단 도구로 원인을 찾고 JVM을 튜닝하는 법 |
이 세 편을 관통하는 원칙은 두 가지입니다.
-
힙 메모리는 참조 관리가 전부다 객체에 대한 참조를 언제 끊을 것인지를 명확히 설계해야 합니다.
static컬렉션, 리스너, 내부 클래스가 대표적인 누수 지점입니다. -
네이티브 메모리는 재사용이 전부다
HttpClient,SslContext, Direct Buffer, 스레드 같은 무거운 자원은 한 번 생성해서 재사용해야 합니다. 매 요청마다 새로 만드는 순간 RSS는 걷잡을 수 없이 늘어납니다.
진단 도구는 원인을 찾는 수단이고, JVM 옵션은 결과를 제어하는 수단일 뿐입니다. 문제의 해결은 결국 코드에 있습니다. 이번 시리즈가 메모리 문제를 만났을 때 어디서부터 손대야 할지 판단하는 데 도움이 되기를 바랍니다.
- jstat↑
- JDK에 기본 포함된 명령어로, Eden/Survivor/Old 영역의 사용량과 GC 횟수·시간을 주기적으로 출력한다. 애플리케이션을 멈추지 않고 사용할 수 있어 운영 환경에서 첫 단계 진단 도구로 활용한다.
- jmap↑
- jmap -histo로 클래스별 인스턴스 수와 메모리 사용량을, jmap -dump로 전체 힙 스냅샷(.hprof 파일)을 생성한다. 힙 덤프는 Eclipse MAT 같은 도구로 분석하여 메모리 누수 원인을 추적한다.
- 힙 덤프(Heap Dump)↑
- JVM이 사용 중인 모든 객체, 참조 관계, 스레드 상태를 담은 바이너리 파일(.hprof)이다. Eclipse MAT, VisualVM 등으로 열어 어떤 객체가 메모리를 차지하고 있는지, 왜 GC되지 않는지 분석할 수 있다.
- NMT(Native Memory Tracking)↑
- -XX:NativeMemoryTracking 옵션으로 활성화하며, jcmd VM.native_memory 명령으로 리포트를 조회한다. Java Heap, Thread, Class, Code Cache, Internal(Direct Buffer) 등 영역별 예약/커밋 메모리를 보여준다. JNI 라이브러리의 malloc은 포함되지 않는다.
- RSS(Resident Set Size)↑
- OS가 측정하는 실제 메모리 점유량이다. 힙, 네이티브 메모리, 스레드 스택, JNI 라이브러리 등 프로세스가 사용하는 모든 물리 메모리를 포함한다. -Xmx보다 RSS가 훨씬 크면 네이티브 메모리 누수를 의심한다.
- G1GC(Garbage First GC)↑
- 힙을 여러 개의 Region으로 나누고, 가비지가 많은 Region부터 수집한다. 일시 정지 시간을 -XX:MaxGCPauseMillis로 목표 설정할 수 있으며, 수 GB~수십 GB 힙에서 예측 가능한 응답성을 제공한다.
- ZGC(Z Garbage Collector)↑
- 일시 정지 시간을 힙 크기와 무관하게 밀리초 단위로 유지하는 것이 목표인 GC다. 수십 GB~TB급 대용량 힙과 엄격한 응답시간 SLA가 필요한 서비스에 적합하다.
- Stop-The-World(STW)↑
- GC가 객체 참조 관계를 안전하게 분석하기 위해 모든 애플리케이션 스레드를 일시 정지시키는 구간이다. Full GC에서 특히 길며, 이 시간이 길어지면 사용자 요청 타임아웃이나 응답 지연의 원인이 된다.
- Dominator Tree↑
- 객체 A가 GC되면 함께 GC될 모든 객체의 합계가 A의 retained size이며, 이 관계를 트리로 정리한 것이 Dominator Tree다. 일반 참조 그래프는 한 객체가 여러 부모를 가질 수 있지만 Dominator Tree는 객체마다 단일 부모(dominator)로 단순화되어 '진짜로 메모리를 붙잡고 있는 범인'을 한눈에 보여준다.
- GC Roots↑
- JVM은 GC Roots에서 도달할 수 없는 객체를 가비지로 판정한다. 대표적인 GC Roots에는 활성 스레드의 스택 변수, static 필드, JNI 글로벌 참조, 동기화 락 객체 등이 있다. 메모리 누수는 본질적으로 '더는 필요 없는 객체가 GC Root로부터 도달 가능한 상태로 남아있는 것'이며, MAT의 Path to GC Roots 기능으로 그 경로를 역추적한다.
- Retained Size↑
- Shallow Size가 객체 자신만의 크기라면, Retained Size는 그 객체가 dominator인 모든 하위 객체의 크기까지 포함한다. 예를 들어 HashMap의 Shallow Size는 수십 바이트지만, 안에 100MB 데이터가 들어있다면 Retained Size는 100MB+가 된다. 누수 분석은 항상 Retained Size 기준으로 정렬해야 진짜 범인을 찾을 수 있다.

